参考:使用 Stata 绘制中国省级地图!比例尺、指北针、秦岭-淮河线、胡焕庸线、海岸线
代码:github
笔记
填充地图
离散变量填充地图
连续变量填充地图
加小部件——矩形
加小部件——饼图
描点——点的大小表示另外一个变量
距离秦岭——淮河越近,点越小,距离越远,点越大。
*画多边形
chinaprov40_db.dta //属性文件
chinaprov40_coord.dta //坐标文件
*画线条和框线
chinaprov40_line_db.dta
chinaprov40_line_coord.dta
*标签的位置
chinaprov40_label.dta
*画比例尺和指南针的多边形
polygon.dta
*画最简单的地图
use chinaprov40_db.dta,clear
*use chinaprov40_coord.dta,clear
spmap using chinaprov40_coord.dta,id(ID)
*加九段线和比例尺、胡焕庸线等
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord.dta))
*use chinaprov40_line_coord.dta,clear
*use chinaprov40_line_db.dta,clear //查看每一个ID对应的属性
*删掉胡焕庸线
*use chinaprov40_line_db.dta,clear //查看每一个ID对应的属性
*_ID=41
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord.dta) ///
select(drop if _ID ==44))
*删掉秦岭淮河线
*use chinaprov40_line_db.dta,clear //查看每一个ID对应的属性
*_ID=38
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord.dta) ///
select(drop if _ID ==44 |_ID ==38))
*查看省与属性的一一对应关系
use chinaprov40_line_coord.dta,clear
ren _ID ID
merge m:1 ID using chinaprov40_line_db.dta
contract group 省
*group 类别
*1 省界线
*2 国界线
*3 海岸线
*4 秦岭-淮河线
*5 小地图框格
*6 指北针/比例尺
*7 胡焕庸线
*group的作用,不同的线条使用不同的粗细和颜色
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord.dta) ///
*select(drop if _ID ==44 |_ID ==38) ///
by(group) size(vvthin *1.2 *0.5 *1.2 *0.5 *0.5 *1.2 )///
color(white black blue%50 green black black red))
*填充比例尺的颜色——polygon
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord.dta) ///
*select(drop if _ID ==44 |_ID ==38) ///
by(group) size(vvthin *1.2 *0.5 *1.2 *0.5 *0.5 *1.2 ) ///
color(white black blue%50 green black black red)) ///
polygon(data(polygon.dta) fcolor(black)) ///画多边形
*加省份标签
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord.dta) ///
*select(drop if _ID ==44 |_ID ==38) ///
by(group) size(vvthin *1.2 *0.5 *1.2 *0.5 *0.5 *1.2 ) ///
color(white black blue%50 green black black red)) ///
polygon(data(polygon.dta) fcolor(black)) /// //画多边形
label(data(chinaprov40_label.dta) x(X) y(Y) label(cname)) //画中文标签
*不要南海诸岛和指北针的标签
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord.dta) ///
*select(drop if _ID ==44 |_ID ==38) ///
by(group) size(vvthin *1.2 *0.5 *1.2 *0.5 *0.5 *1.2 ) ///
color(white black blue%50 green black black red)) ///
polygon(data(polygon.dta) fcolor(black)) /// //画多边形
label(data(chinaprov40_label.dta) x(X) y(Y) label(cname) ///
*select(drop if cname=="南海诸岛")) //画中文标签
select(drop if inlist(cname,"南海诸岛","N","1000km")) //画中文标签
*如何移动指北针和比例尺
线条-多边形和
use chinaprov40_line_coord.dta,clear
use chinaprov40_line_db.dta,clear
replace _X = _X+3000000 if inlist(_ID,40,41)
replace _Y = _Y+4000000 if inlist(_ID,40,41) //单位是米
save chinaprov40_line_coord2.dta,replace
*画出坐标系,以确定X轴和Y轴要移动多少——freestyle
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord.dta) ///
*select(drop if _ID ==44 |_ID ==38) ///
by(group) size(vvthin *1.2 *0.5 *1.2 *0.5 *0.5 *1.2 ) ///
color(white black blue%50 green black black red)) ///
polygon(data(polygon.dta) fcolor(black)) /// //画多边形
label(data(chinaprov40_label.dta) x(X) y(Y) label(cname)) freestyle//画中文标签
*移动线条
use polygon.dta,clear
replace _X = _X+3000000 if _ID==38
replace _Y = _Y+4000000 if _ID==38
save polygon2.dta,replace
use chinaprov40_label.dta,clear
replace X = X + 3000000 if cname=="N"
replace Y = Y + 4000000 if cname=="N"
save chinaprov40_label2.dta,replace
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord2.dta) ///
*select(drop if _ID ==44 |_ID ==38) ///
by(group) size(vvthin *1.2 *0.5 *1.2 *0.5 *0.5 *1.2 ) ///
color(white black blue%50 green black black red)) ///
polygon(data(polygon2.dta) fcolor(black)) /// //画多边形
label(data(chinaprov40_label2.dta) x(X) y(Y) label(cname))
*同时移动指北针和比例尺
use chinaprov40_line_coord.dta,clear
replace _X = _X+3000000 if inlist(_ID,40,41)
replace _Y = _Y+4000000 if inlist(_ID,40,41)
replace _Y = _Y+200000 if inlist(_ID,42,43)
save chinaprov40_line_coord2.dta,replace
use polygon.dta,clear
replace _X = _X+3000000 if _ID==38
replace _Y = _Y+4000000 if _ID==38
replace _Y = _Y+200000 if _ID==39
save polygon2.dta,replace
use chinaprov40_label.dta,clear
replace X = X + 3000000 if cname=="N"
replace Y = Y + 4000000 if cname=="N"
replace Y = Y + 200000 if cname=="1000km"
save chinaprov40_label2.dta,replace
use chinaprov40_db.dta,clear
spmap using chinaprov40_coord.dta,id(ID) ///
line(data(chinaprov40_line_coord2.dta) ///
*select(drop if _ID ==44 |_ID ==38) ///
by(group) size(vvthin *1.2 *0.5 *1.2 *0.5 *0.5 *1.2 ) ///
color(white black blue%50 green black black red)) ///
polygon(data(polygon2.dta) fcolor(black)) /// //画多边形
label(data(chinaprov40_label2.dta) x(X) y(Y) label(cname) size(*0.8))/// 设置标签小一点
graphr(margin(medium))// 调整边距,放大
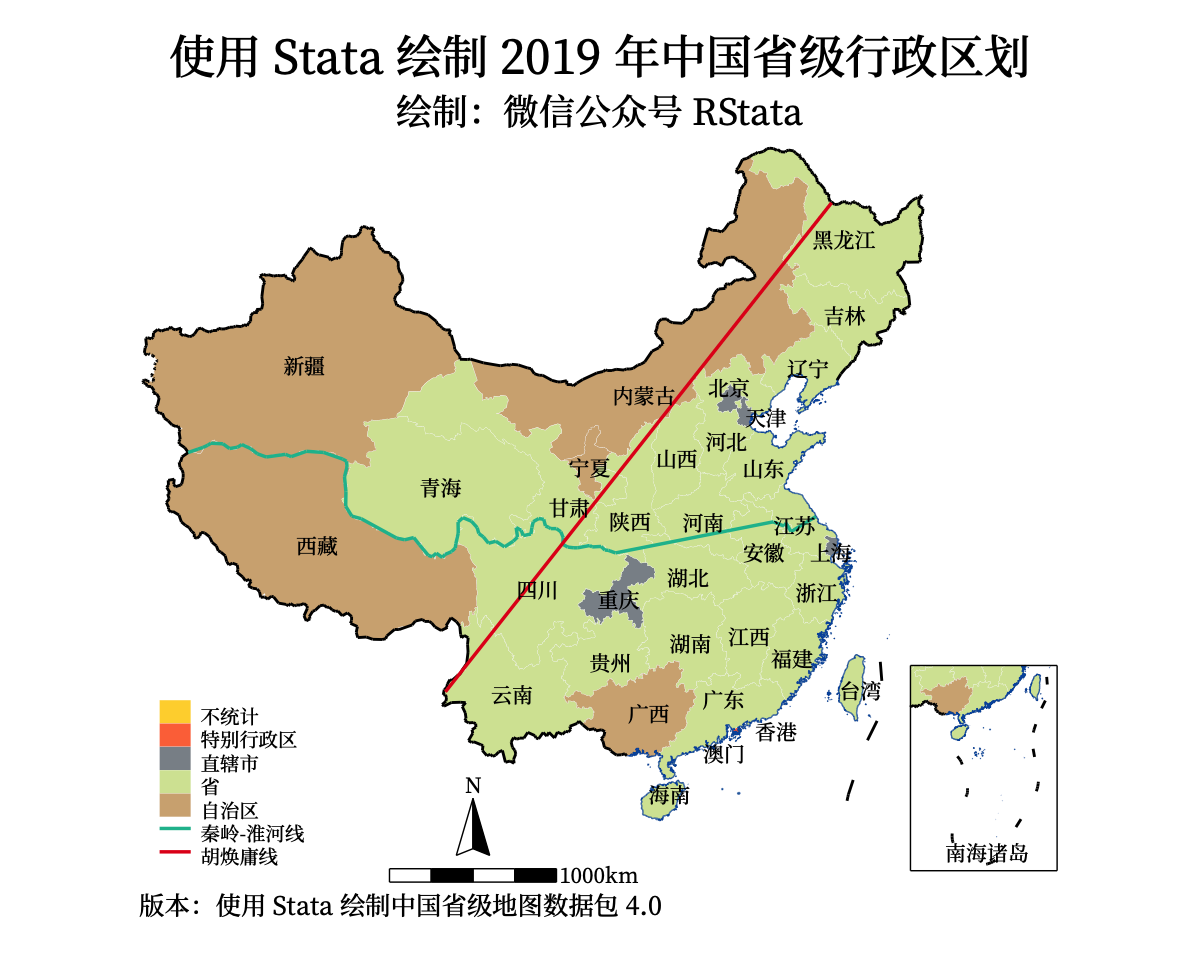
*案例一:2019年中国省级行政区域
use chinaprov40_db.dta,clear
encode 类型,gen(type)
codebook type //查看数-标签对照
*注意 stata15(含)使用spmap,15之后就可以使用grmap,第一次使用需要激活
*grmap,activate
*使用grmap和spmap的结果是一样的,spmap是第三方,grmap是官方
grmap type using chinaprov40_coord.dta,id(ID) /// //不需要改动底图,只需要添加type进行填充
line(data(chinaprov40_line_coord2.dta) ///
*select(drop if _ID ==44 |_ID ==38) ///
by(group) size(vvthin *1.2 *0.5 *1.2 *0.5 *0.5 *1.2 ) ///
color(white /// 省界颜色
black /// 国界线颜色
"0 85 170" /// 海岸线颜色
"24 188 156" /// 秦岭淮河线颜色
black /// 小地图框格颜色
black /// 比例尺和指北针颜色
"227 26 28" /// 胡焕庸线颜色
)) ///
polygon(data(polygon2.dta) fcolor(black)) /// //画多边形
label(data(chinaprov40_label2.dta) x(X) y(Y) label(cname) size(*0.8))/// 设置标签小一点
graphr(margin(medium))// 调整边距,放大
*想要的是每一种type对应一种颜色,但图形是分组1-4,4-5
重新设定分组
help spmap
*clmethod(custom) clbreak(0 1 2 3 4 5) 自定义分组,分成五组
fcolor("254 212 57" "253 116 70" "138 145 151" "213 228 162" "210 175 129") ///自己填充颜色,可选择渐变色
*gr export test.pdf,replace
osize(vvthin ...)/// outline 边框线(省界)的大小 ...表示所有的图层
ocolor(white ...) ///颜色为白色
legend(order(2 "不统计" 3 "特别行政区" 4 "直辖市" 5 "省" 6 "自治区" 11 "秦岭-淮河线" 14 "胡焕庸线"))
ti("使用 Stata 绘制 2019 年中国省级行政区划") ///
subti("绘制:微信公众号 RStata") ///
caption("版本:使用 Stata 绘制中国省级地图数据包 4.0", size(*0.8))
gr export pic1.png, replace width(1200)
*使用graph editor查看图层对应
案例一:全部代码
离散变量的绘制
use chinaprov40_db.dta, clear
encode 类型, gen(type)
codebook type
grmap type using chinaprov40_coord.dta, ///
id(ID) osize(vvthin ...) ocolor(white ...) ///
clmethod(custom) clbreaks(0 1 2 3 4 5) ///
fcolor("254 212 57" "253 116 70" "138 145 151" "213 228 162" "210 175 129") ///
leg(order(2 "不统计" 3 "特别行政区" 4 "直辖市" 5 "省" 6 "自治区" 11 "秦岭-淮河线" 14 "胡焕庸线")) ///
graphr(margin(medium)) ///
line(data(chinaprov40_line_coord.dta) by(group) size(vvthin *1 *0.5 *1.2 *0.5 *0.5 *1.2) pattern(solid ...) ///
color(white /// 省界颜色
black /// 国界线颜色
"0 85 170" /// 海岸线颜色
"24 188 156" /// 秦岭淮河线颜色
black /// 小地图框格颜色
black /// 比例尺和指北针颜色
"227 26 28" /// 胡焕庸线颜色
)) ///
polygon(data(polygon) fcolor(black) ///
osize(vvthin)) ///
label(data(chinaprov40_label) x(X) y(Y) label(cname) length(20) size(*0.8)) ///
ti("使用 Stata 绘制 2019 年中国省级行政区划") ///
subti("绘制:微信公众号 RStata") ///
caption("版本:使用 Stata 绘制中国省级地图数据包 4.0", size(*0.8))
gr export pic1.png, replace width(1200)
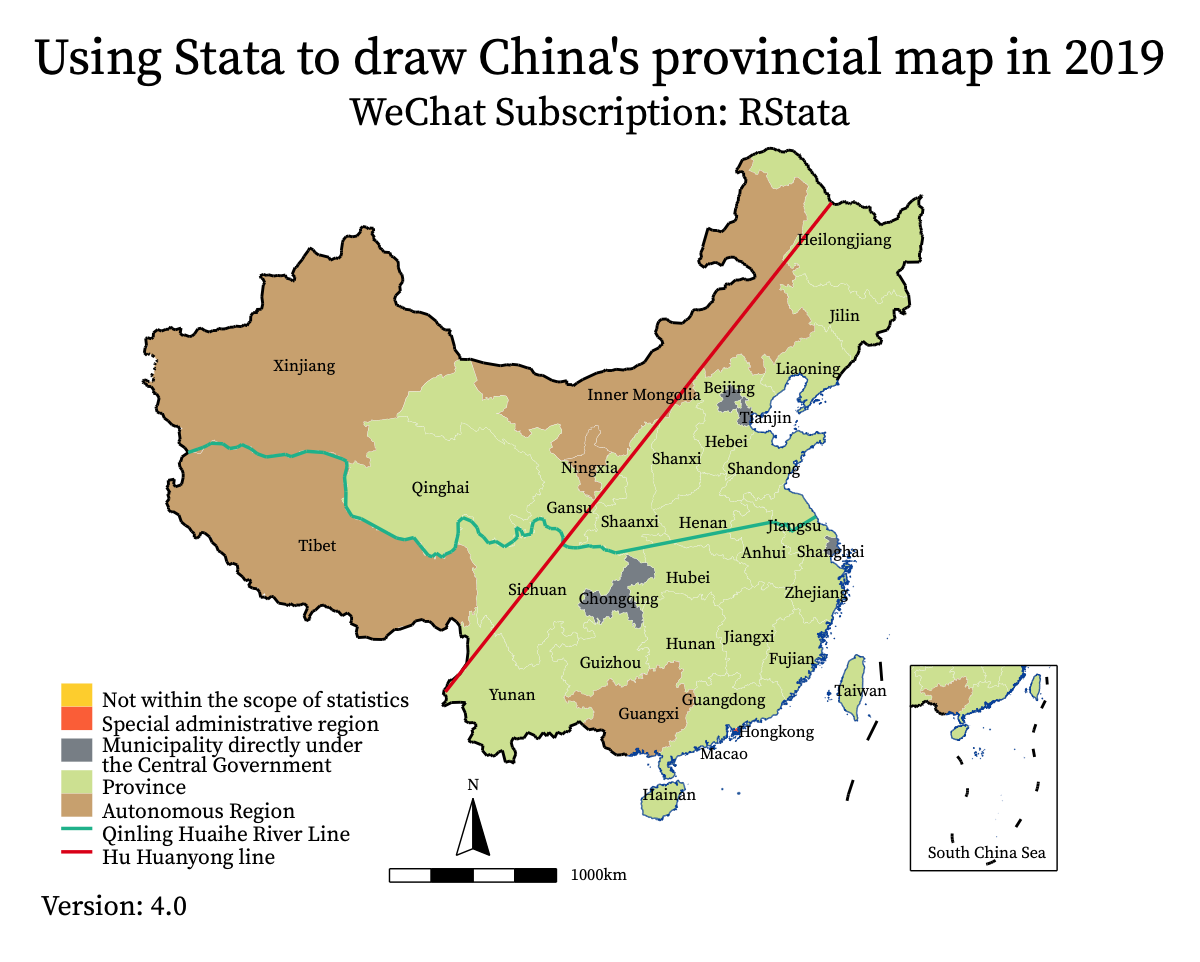
案例二-案例一的英文版本
*chinaprov40_label.dta 数据决定了文本标签的位置和内容,如果想绘制英文版的地图,可以使用 ename 变量:
grmap type using chinaprov40_coord.dta, ///
id(ID) osize(vvthin ...) ocolor(white ...) ///
clmethod(custom) clbreaks(0 1 2 3 4 5) ///
fcolor("254 212 57" "253 116 70" "138 145 151" "213 228 162" "210 175 129") ///
leg(order(2 "Not within the scope of statistics" 3 "Special administrative region" 4 "Municipality directly under" "the Central Government" 5 "Province" 6 "Autonomous Region" 11 "Qinling Huaihe River Line" 14 "Hu Huanyong line")) /// 换行
graphr(margin(medium)) ///
line(data(chinaprov40_line_coord.dta) by(group) size(vvthin *1 *0.5 *1.2 *0.5 *0.5 *1.2) pattern(solid ...) ///
color(white /// 省界颜色
black /// 国界线颜色
"0 85 170" /// 海岸线颜色
"24 188 156" /// 秦岭淮河线颜色
black /// 小地图框格颜色
black /// 比例尺和指北针颜色
"227 26 28" /// 胡焕庸线颜色
)) ///
polygon(data(polygon) fcolor(black) ///
osize(vvthin)) ///
label(data(chinaprov40_label) x(X) y(Y) label(ename) length(20) size(*0.6)) ///标签长度和大小
ti("Using Stata to draw China's provincial map in 2019") ///
subti("WeChat Subscription: RStata") ///
caption("Version: 4.0", size(*0.8))
gr export pic2.png, replace width(1200)
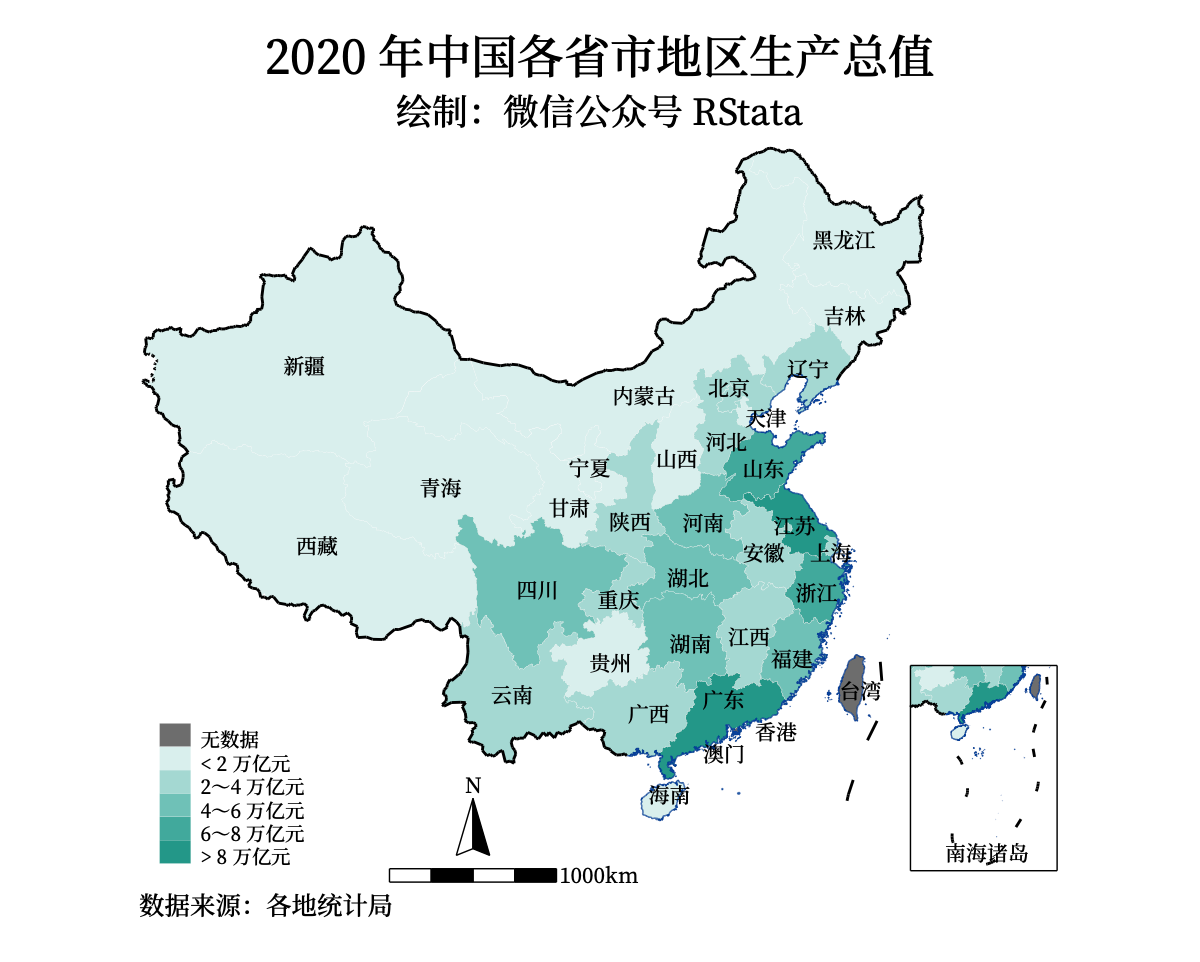
案例三:连续变量
*连续变量的绘制方法和离散变量的类似,通过恰当的分组和颜色填充就可以绘制出精美的图表了,下面以2020 年中国各省市地区生产总值的填充地图绘制为例:
import delimited using "2020年中国各省市地区生产总值.csv", clear encoding(utf8)
gen prov = substr(省份, 1, 6)
save 2020年中国各省市地区生产总值, replace
use chinaprov40_db.dta, clear
gen prov = substr(省, 1, 6) //省份的前两个字
merge 1:1 prov using 2020年中国各省市地区生产总值
replace 地区生产总值 = -1 if missing(地区生产总值)// 缺失值,缺失也可以填充颜色
grmap 地区生产总值 using chinaprov40_coord.dta, ///
id(ID) osize(vvthin ...) ocolor(white ...) ///
clmethod(custom) clbreaks(-1 0 20000 40000 60000 80000 120000) ///
fcolor(gray "224 242 241" "178 223 219" "128 203 196" "77 182 172" "38 166 154") ///
leg(order(2 "无数据" 3 "< 2 万亿元" 4 "2~4 万亿元" 5 "4~6 万亿元" 6 "6~8 万亿元" 7 "> 8 万亿元")) ///
graphr(margin(medium)) ///
line(data(chinaprov40_line_coord.dta) ///
/// 去除秦岭淮河线(4)、胡焕庸线(7)
select(keep if inlist(group, 1, 2, 3, 5, 6)) ///
by(group) size(vvthin *1 *0.5 *0.5 *0.5) ///
pattern(solid ...) ///
color(white /// 省界颜色
black /// 国界线颜色
"0 85 170" /// 海岸线颜色
black /// 小地图框格颜色
black /// 比例尺和指北针颜色
)) ///
polygon(data(polygon) fcolor(black) ///
osize(vvthin)) ///
label(data(chinaprov40_label) x(X) y(Y) label(cname) length(20) size(*0.8)) ///
ti("2020 年中国各省市地区生产总值") ///
subti("绘制:微信公众号 RStata") ///
caption("数据来源:各地统计局", size(*0.8))
gr export pic3.png, replace width(1200)
主要关注怎么分组,怎么设定颜色,怎么设定图例?
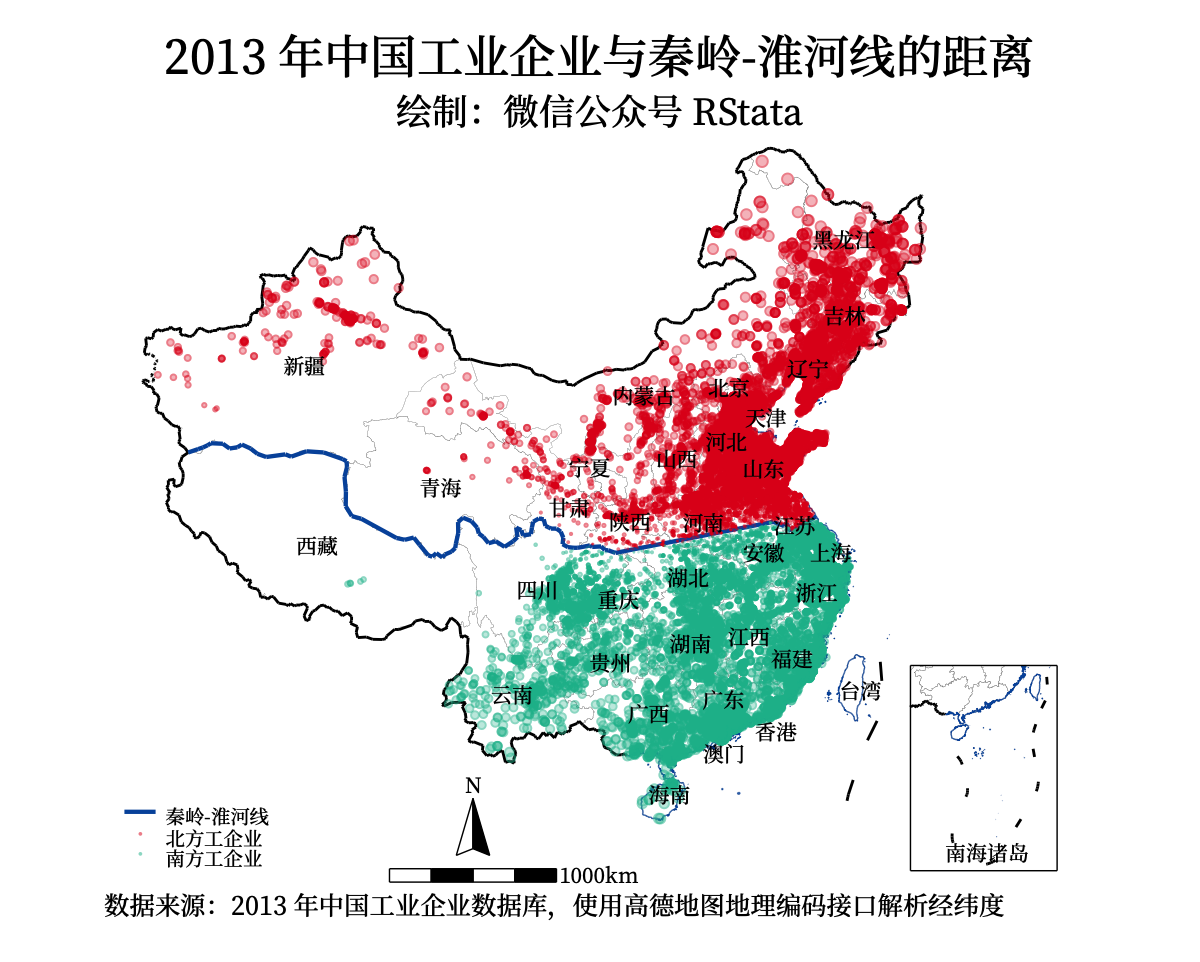
案例四:2013年中国工业企业分布及距离秦岭淮河的距离
*转换坐标,经纬度到笛卡尔坐标系
* 转换方式一:https://czxb.shinyapps.io/crs-trans/
* 注意事项,上传的 csv 文件应该包含数值型的 lon 和 lat 变量,观测值上限大概是 10 万个,不可多人同时使用。
use gq2013sample.dta,clear
keep *度
ren 经度 lon
ren 维度 lat
export delimited using "待上传.csv",replace
import delimited using "转换后的数据.csv",clear
gen id = _n
save 转换后的数据,replace
use gq2013sample.dta,clear
gen id=_n
merge 1:1 id using "转换后的数据"
keep x y 与秦岭淮河线的距离 北方或南方
encode 北方或南方,gen(north)
save pointdata,replace
use chinaprov40_db.dta, clear
spmap using chinaprov40_coord.dta, id(ID) /// 不需要填充
ocolor("black" ...) osize(vvthin ...) ///
line(data(chinaprov40_line_coord.dta) ///
/// 胡焕庸线(7)
select(keep if inlist(group, 1, 2, 3, 4, 5, 6)) ///
by(group) size(vvthin *1 *0.5 *1.5 *0.5 *0.5) ///
pattern(solid ...) ///
color(white /// 省界颜色
black /// 国界线颜色
"0 85 170" /// 海岸线颜色
"0 85 170" /// 秦岭淮河线颜色
black /// 小地图框格颜色
black /// 比例尺和指北针颜色
)) ///
polygon(data(polygon) fcolor(black) ///
osize(vvthin)) ///
label(data(chinaprov40_label) x(X) y(Y) label(cname) length(20) size(*0.8)) ///
point(data(pointdata) by(north) ///
fcolor("227 26 28%30" "24 188 156%30") ///
x(x) y(y) ///
proportional(与秦岭淮河线的距离) /// 点的大小
size(*0.1) legenda(on)) ///
leg(order(7 "秦岭-淮河线" 10 "北方工企业" 11 "南方工企业")) ///
ti("2013 年中国工业企业与秦岭-淮河线的距离", color(black)) ///
subti("绘制:微信公众号 RStata") ///
graphr(margin(medium)) ///
caption("数据来源:2013 年中国工业企业数据库,使用高德地图地理编码接口解析经纬度", size(*0.8))
gr export pic4.png, replace width(1200)
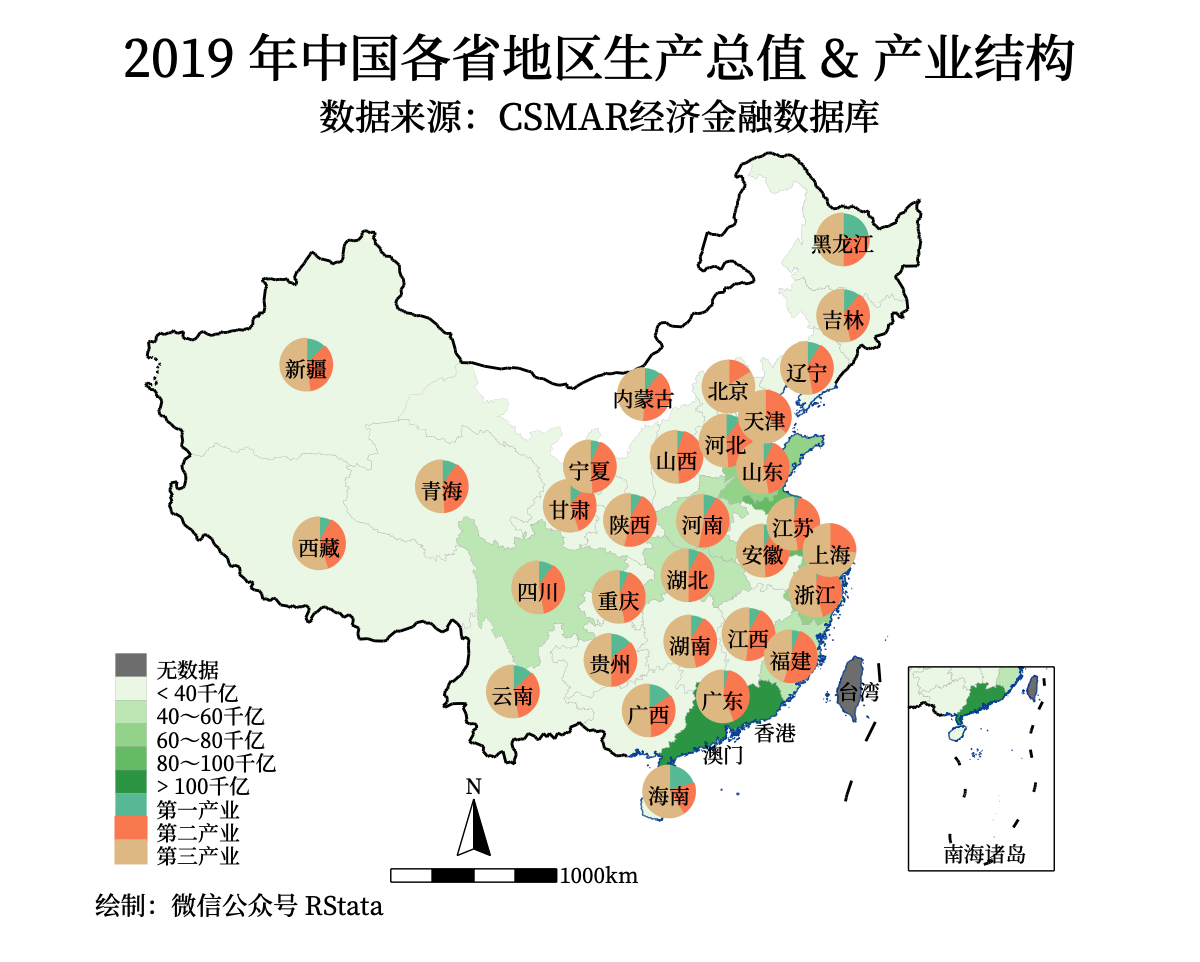
案例五:加饼图
饼图的位置可以用标签位置:
use 各省历年GDP, clear
drop if 省份 == "中国"
replace 地区生产总值_亿元 = 地区生产总值_亿元 / 1000
merge m:m 省代码 using chinaprov40_db.dta
replace 地区生产总值_亿元 = -1 if missing(年份)
grmap 地区生产总值_亿元 if 年份 == 2019 | missing(年份) ///
using chinaprov40_coord.dta, id(ID) ///
clmethod(custom) clbreaks(-1 0 40 60 80 100 120) ///
fcolor("gray" "237 248 233" "199 233 192" "161 217 155" "116 196 118" "49 163 84") ///
ocolor("gray" ...) ///
ti("2019 年中国各省地区生产总值 & 产业结构", size(*1.1)) ///
subtitle("数据来源:CSMAR经济金融数据库") ///
graphr(margin(medium)) ///
osize(vvthin ...) ///
legend(size(*1.1) ///
order(2 "无数据" 3 "< 40千亿" ///
4 "40~60千亿" 5 "60~80千亿" ///
6 "80~100千亿" 7 "> 100千亿" ///
14 "第一产业" 15 "第二产业" 16 "第三产业")) ///
caption("绘制:微信公众号 RStata", size(*0.8)) ///
line(data(chinaprov40_line_coord.dta) ///
/// 去除秦岭淮河线(4) 胡焕庸线(7)
select(keep if inlist(group, 1, 2, 3, 5, 6)) ///
by(group) size(vvthin *1 *0.5 *0.5 *0.5) ///
pattern(solid ...) ///
color(white /// 省界颜色
black /// 国界线颜色
"0 85 170" /// 海岸线颜色
black /// 小地图框格颜色
black /// 比例尺和指北针颜色
)) ///
polygon(data(polygon) fcolor(black) ///
osize(vvthin)) ///
label(data(chinaprov40_label) x(X) y(Y) label(cname) length(20) size(*0.8)) ///
diagram(data(piedata) x(X) y(Y) v(第一产业占GDP比重_百分比 第二产业占GDP比重_百分比 第三产业占GDP比重_百分比) ///
type(pie) legenda(on) os(vvthin) ///
size(1.5) fc("102 194 165" "252 141 98" "229 196 148") ///
oc("102 194 165" "252 141 98" "229 196 148"))
gr export "pic5.png", replace width(1200)
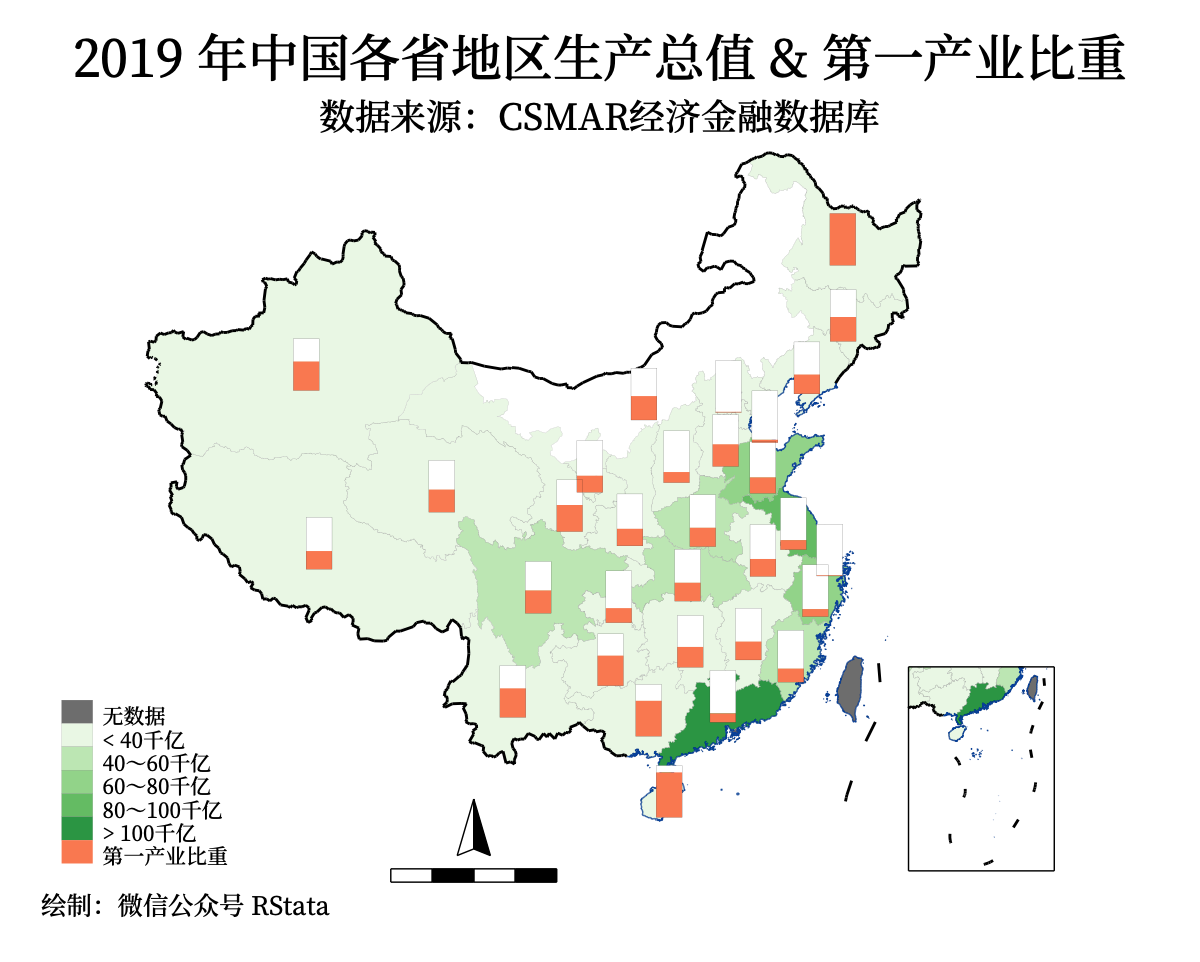
饼图也可以换成框架矩形图:
grmap 地区生产总值_亿元 if 年份 == 2019 | missing(年份) ///
using chinaprov40_coord.dta, id(ID) ///
clmethod(custom) clbreaks(-1 0 40 60 80 100 120) ///
fcolor("gray" "237 248 233" "199 233 192" "161 217 155" "116 196 118" "49 163 84") ///
ocolor("gray" ...) ///
ti("2019 年中国各省地区生产总值 & 第一产业比重", size(*1.1)) ///
subtitle("数据来源:CSMAR经济金融数据库") ///
graphr(margin(medium)) ///
osize(vvthin ...) ///
legend(size(*1.1) ///
order(2 "无数据" 3 "< 40千亿" ///
4 "40~60千亿" 5 "60~80千亿" ///
6 "80~100千亿" 7 "> 100千亿" ///
15 "第一产业比重")) ///
caption("绘制:微信公众号 RStata", size(*0.8)) ///
line(data(chinaprov40_line_coord.dta) ///
/// 去除秦岭淮河线(4) 胡焕庸线(7)
select(keep if inlist(group, 1, 2, 3, 5, 6)) ///
by(group) size(vvthin *1 *0.5 *0.5 *0.5) ///
pattern(solid ...) ///
color(white /// 省界颜色
black /// 国界线颜色
"0 85 170" /// 海岸线颜色
black /// 小地图框格颜色
black /// 比例尺和指北针颜色
)) ///
polygon(data(polygon) fcolor(black) ///
osize(vvthin)) ///
diagram(data(piedata) x(X) y(Y) v(第一产业占GDP比重_百分比) ///
type(frect) legenda(on) os(vvthin) ///
size(1.5) fc("252 141 98") ///
oc("252 141 98") refsize(none))
gr export "pic6.png", replace width(1200)
案例六:各省人口密度
最后我们再演示下胡焕庸线的用法:
use 中国人口空间分布省级面板数据集.dta, clear
ren 省份 省
merge m:1 省 using chinaprov40_db.dta
keep if 年份 == 2015 | missing(年份)
replace 均值 = -1 if missing(均值)
grmap 均值 using chinaprov40_coord.dta, ///
id(ID) osize(vvthin ...) ocolor(white ...) ///
clmethod(custom) clbreaks(-1 0 100 1000 2000 3000 4000) ///
fcolor(gray "224 242 241" "178 223 219" "128 203 196" "77 182 172" "38 166 154") ///
leg(order(2 "无数据" 3 "< 100 人/平方公里" 4 "100~1000 人/平方公里" 5 "1000~2000 人/平方公里" 6 "2000~3000 人/平方公里" 7 "> 3000 人/平方公里" 14 "胡焕庸线")) ///
graphr(margin(medium)) ///
line(data(chinaprov40_line_coord.dta) ///
/// 去除秦岭淮河线(4)
select(keep if inlist(group, 1, 2, 3, 5, 6, 7)) ///
by(group) size(vvthin *1 *0.5 *0.5 *0.5 *1.2) ///
pattern(solid ...) ///
color(white /// 省界颜色
black /// 国界线颜色
"0 85 170" /// 海岸线颜色
black /// 小地图框格颜色
black /// 比例尺和指北针颜色
"227 26 28" /// 胡焕庸线颜色
)) ///
polygon(data(polygon) fcolor(black) ///
osize(vvthin)) ///
label(data(chinaprov40_label) x(X) y(Y) label(cname) length(20) size(*0.8)) ///
ti("2015 年中国各省平均人口密度") ///
subti("绘制:微信公众号 RStata") ///
caption("数据来源:中国科学院资源环境科学与数据中心", size(*0.8))
gr export pic7.png, replace width(1200)
【Stata】绘制一份完完整整的中国地图!
文件准备:.shp和.dbf
转换文件:转换为stata可以识别的.dta
使用spmap命令绘图
找shp文件的方法:
stata自带命令提供的中国地图是不完整的,是不能使用的;另外,不过这个地图画出来也只能做ppt的演示,在国内发文章需要有正规的审图号,没审图号,发英文可以,中文期刊比较严格
阿里云地图选择器:http://datav.aliyun.com/tools/atlas/index.html
在json格式,优点,在后续倒入快很多
shp格式转换:https://mapshaper.org/

底图+指标
也可以不使用stata画九段线,使用没有九段线的图和带九段线的图,在ppt中合并为1张图
stata 画二维地图
1. 简介
二维地图很复杂,但是并不在于他们有多难画,而在于我们往往难以预料到画完的结果。很多时候我们很难绘制想要的图,但是一个像下面这样非常漂亮的图,无疑可以为我们的论文增添不少光彩。下面就让我们看看如何绘制二维地图吧!
2. 准备工作
首先安装如下命令,并进行相关设置。
ssc install geo2xy, replace // 用来调整地图的映射
ssc install schemepack, replace // Stata绘图模板仓库
set scheme white_tableau // 设置绘图模板
graph set window fontface "Arial Narrow" // 设置绘图字体
然后下载数据「CC-EST2020-ALLDATA6.csv」,并做一些数据清理的工作。
import delim CC-EST2020-ALLDATA6.csv, clear
tab year
keep if year==13 // 2020
keep if agegrp==0 // TOTAL
drop year agegrp
keep sumlev state county stname ctyname tot_pop ba_male ba_female h_male h_female aa_male aa_female
destring _all, replace
ren state STATEFP
ren county COUNTYFP
gen tot_afam = ba_male + ba_female // african-american
gen tot_hisp = h_male + h_female // hispanic
gen tot_asian = aa_male + aa_female // asian
gen share_afam = (tot_afam / tot_pop) * 100
gen share_hisp = (tot_hisp / tot_pop) * 100
gen share_asian = (tot_asian / tot_pop) * 100
compress
save county_race.dta, replace
接着,下载州和县的 ShapeFiles,即「cb_2018_us_state_500k.zip」。现在,我们从边界开始画起。
spshape2dta cb_2018_us_state_500k.shp,replace saving(usa_state)
以上命令语句是将 .shp 格式的文件转化为 Stata 认识的 .dta 格式的文件。
use usa_state, clear
spmap using usa_state_shp, id(_ID)
很不巧,阿拉斯加实在是太大的,为了后续作图的美观,我们将阿拉斯加和夏威夷群岛去掉,只留下美国本土。为了快速找出这几个不在美国本土的州,我们用下面这个巧妙的方法来得到这些岛屿的识别码。
twoway (scatter _CY _CX, mlabel(STATEFP))
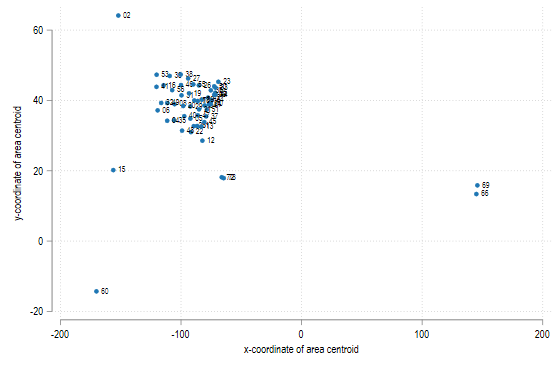
这样我们就找到了需要删掉掉的岛屿的识别码了,他们是 STATEFP = 02, 15, 60, 66, 69, 72, 78
* clean up the boundaries
use usa_state_shp, clear
merge m:1 _ID using usa_state // to get the identifiers
destring STATEFP, replace
drop if inlist(STATEFP,2,15,60,66,69,72,78)
twoway (scatter _Y _X)
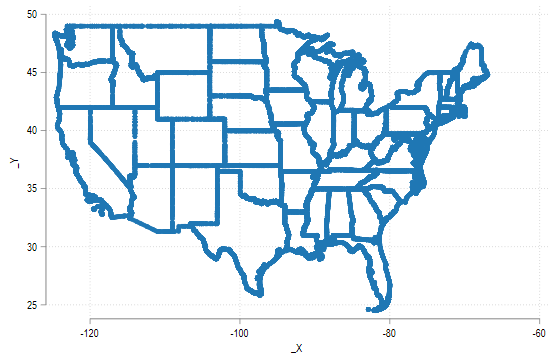
好像和我们平时看到的美国地图不太一样,我们可以采用 geo2xy 这个命令来将经纬度转换到笛卡尔坐标系当中。
geo2xy _Y _X, proj(albers) replace
twoway (scatter _Y _X)
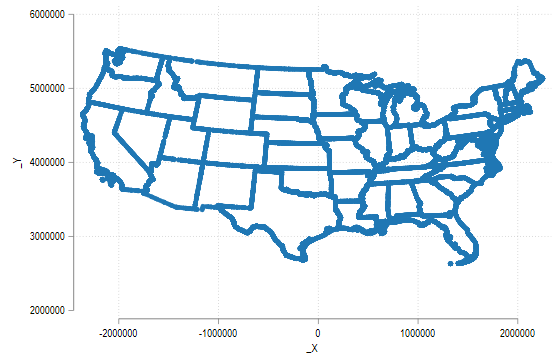
看上去好多了!下面我们简单清理一下数据,然后保存起来。
drop _CX- _merge
sort _ID shape_order
save usa_state_shp_clean.dta, replace
让我们看下此时的地图长啥样。
use usa_state, clear
spmap using usa_state_shp_clean, id(_ID)
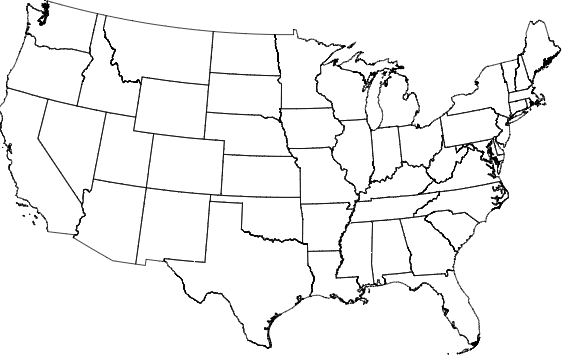
看上去很不错,下面我们再对不同的县做同样的处理,这里需要下载文件「cb_2018_us_county_500k.zip」。
* get the counties in order
spshape2dta "cb_2018_us_county_500k.shp", replace saving(usa_county)
* clean up the boundaries
use usa_county_shp, clear
merge m:1 _ID using usa_county
destring STATEFP, replace
drop if inlist(STATEFP,2,15,60,66,69,72,78)
drop _CX- _merge
geo2xy _Y _X, proj(albers) replace
sort _ID shape_order
save usa_county_shp_clean.dta, replace
* 绘制地图
use usa_county, clear
destring _all, replace
spmap using usa_county_shp_clean, id(_ID)
3. 地图
首先让我们把需要的数据全部合并到一份文件当中。
use usa_county, clear
destring _all, replace
merge 1:1 STATEFP COUNTYFP using county_race
keep if _m==3
drop _m
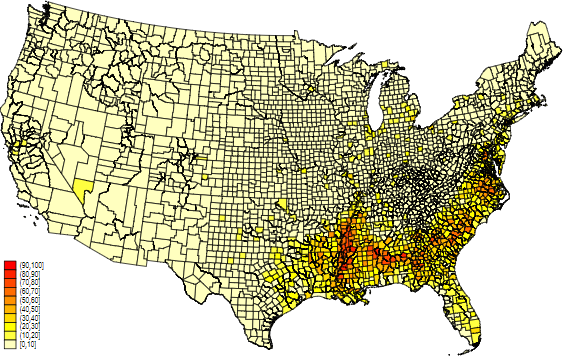
spmap share_afam using usa_county_shp_clean, id(_ID) clm(custom) clb(0(10)100) fcolor(Heat) // 非裔美国人的比例
spmap share_hisp using usa_county_shp_clean, id(_ID) clm(custom) clb(0(10)100) fcolor(Heat) // 拉美裔美国人比例
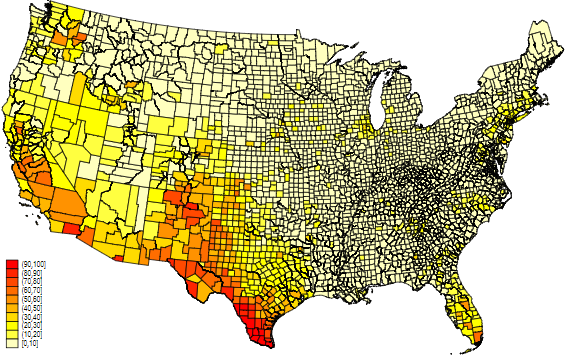
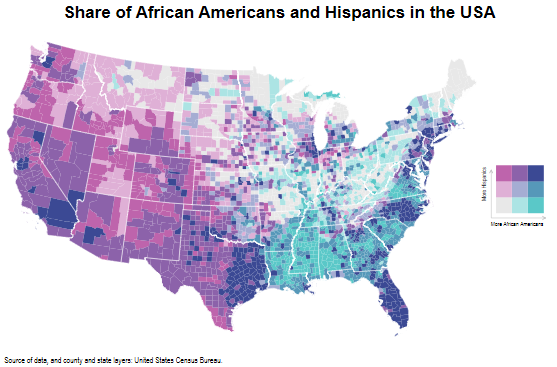
可以看到拉美裔和非裔美国人的分布存在显著差异。我们也可以画一个散点图来直观体现非裔美国人和拉美裔美国人之间的交叠部分。
scatter share_afam share_hisp
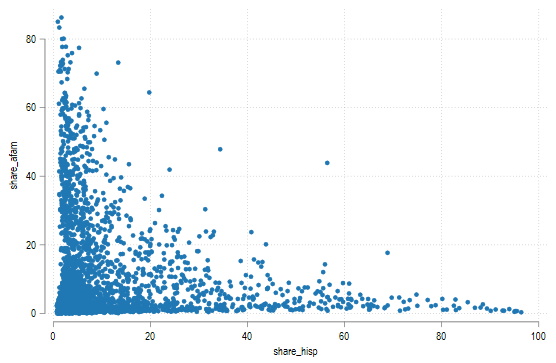
可以发现二者几乎没有什么重叠区域。下面我们将这个散点图按种类分开。对于双变量的地图,我们需要分配 9 种或者 16 种颜色到不同的种类组合。但是在具体分配之前,我们需要做一件重要的事情就是弄清楚颜色分配的顺序。作者给出这样的颜色分配顺序:
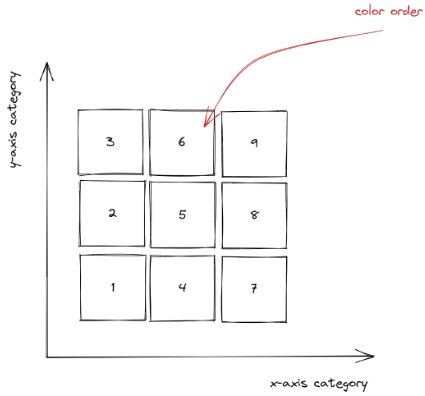
接下来要做的是将数据按照顺序分为 9 组,分组的方式有很多,我们可以采用等分的方式或分位数分组的方式。首先让我们看一下如何采用等分的方式分组,作者给出了一种非常巧妙的方法。
* 将数据进行切分
cap drop cut*
egen cut_afam = cut(share_afam), at(0,33,66,100) icodes
egen cut_hisp = cut(share_hisp), at(0,33,66,100) icodes
egen cut_hisp2 = cut(share_hisp), group(3) icodes // 这个就是分位数
* 分组
sort cut_afam cut_hisp
egen grp_cut = group(cut_afam cut_hisp)
分位数分组数命令如下:
* 分位数
cap drop xtile*
xtile xtile_afam = share_afam, n(3)
xtile xtile_hisp = share_hisp, n(3)
* 分组
sort xtile_afam xtile_hisp
egen grp_xtile = group(xtile_afam xtile_hisp)
下面我们来比较一下这两种分组的结果:
twoway (scatter share_hisp share_afam, msize(small) mc(%10)), yline(0 33 66 100) ///
xline(0 33 66 100) xlabel(0(20)100) ylabel(0(20)100) aspect(1)
* get the cut-off points from tabstat
tabstat share_hisp, by(xtile_hisp) c(stat) stat(max)
tabstat share_afam, by(xtile_afam) c(stat) stat(max)
* based on percentiles
twoway (scatter share_hisp share_afam, msize(small) mc(%10)), yline(0 3 7.4 100) ///
xline(0 1.2 6.5 100) xlabel(0(20)100) ylabel(0(20)100) aspect(1)
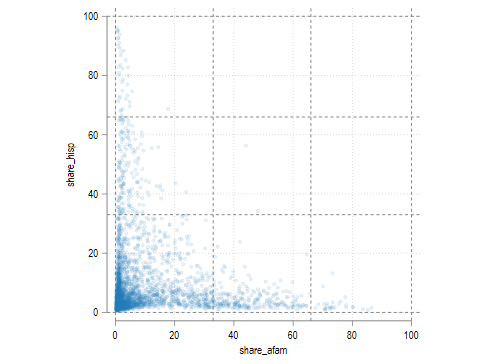
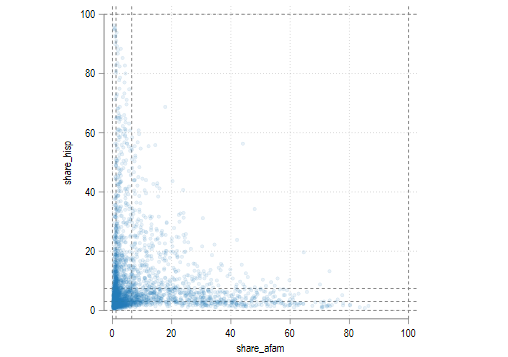
很明显,在等分法画出的图大约 80% 的点都落在左下角的那个方格当中,而在右上角的方格中却没有点,因此等分法的结果并不理想。相比之下以分位数法分组的结果就很理想,分位数的设置使得每一个方格中都有大约相等的点数。所以相比于等分法而言,分位数分组的结果可能会更加理想一些。下面我们检查一下两种分组的结果如何改变地图的格式。
首先是等分的结果:
spmap grp_cut using usa_county_shp_clean, id(_ID) clm(unique) fcolor(Heat)
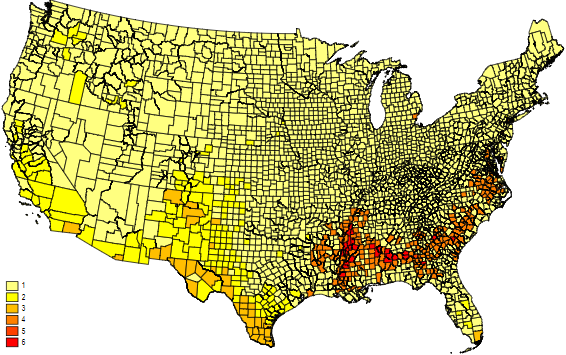
可以看出在等分法分组的情形下并没有什么特别之处,我们划分的 9 类中只有 6 类在图中体现出来了。而且在不同种类中划分地并不均匀。
其次是分位数的结果:
spmap grp_xtile using usa_county_shp_clean, id(_ID) clm(unique) fcolor(Heat)
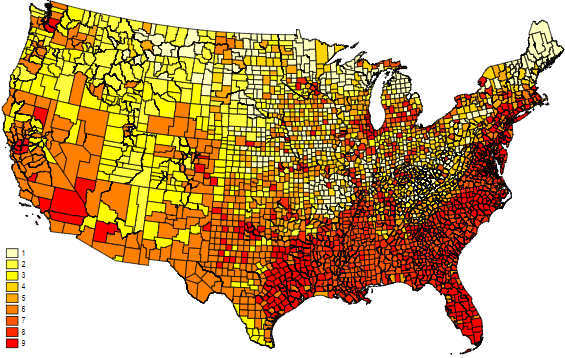
可以看到我们有 1-9 组,而且每一组都大致相等的点。然而有一个小缺陷就是颜色的深浅并不代表任何顺序。
4. 颜色
二维地图的颜色设计需要仔细考虑,它们需要很容易区分并且有着足够的对比度以呈现更为有意义的信息。首先我们挑选一个紫色的模板:
colorpalette #e8e8e8 #dfb0d6 #be64ac #ace4e4 #a5add3 #8c62aa #5ac8c8 #5698b9 #3b4994

下面让我们把颜色放进地图:
* 颜色放进地图
colorpalette #e8e8e8 #dfb0d6 #be64ac #ace4e4 #a5add3 #8c62aa #5ac8c8 #5698b9 #3b4994, nograph
local colors `r(p)'
spmap grp_xtile using usa_county_shp_clean, ///
id(_ID) clm(unique) fcolor("`colors'") ///
ocolor(white ..) osize(0.02 ..) ///
ndfcolor(gs14) ndocolor(gs6 ..) ndsize(0.03 ..) ndlabel("No data") ///
polygon(data("usa_state_shp_clean") ocolor(white) osize(0.15) ) ///
legend(pos(5) size(2.5)) legstyle(2) ///
title("Comparison of African American versus Hispanic shares", size(5)) ///
note("Source: United States Census Bureau", size(vsmall))
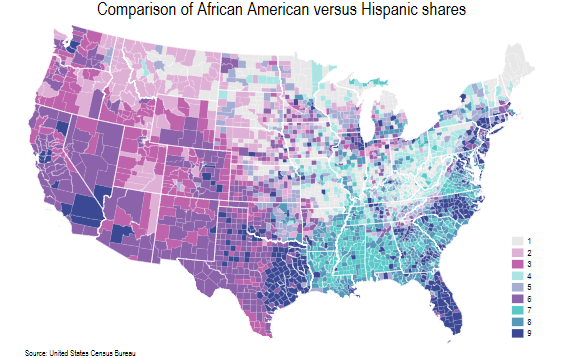
下面让我们去掉一些额外的信息:
colorpalette #e8e8e8 #dfb0d6 #be64ac #ace4e4 #a5add3 #8c62aa #5ac8c8 #5698b9 #3b4994, nograph
local colors `r(p)'
spmap grp_xtile using usa_county_shp_clean, ///
id(_ID) clm(unique) fcolor("`colors'") ///
ocolor(white ..) osize(none ..) ///
ndfcolor(gs14) ndocolor(gs6 ..) ndsize(0.03 ..) ndlabel("No data") ///
polygon(data("usa_state_shp_clean") ocolor(white) osize(0.12) ) ///
legend(off) name(bivar_map, replace)
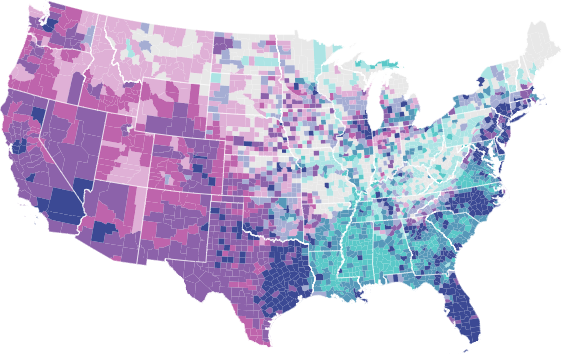
5. 图例
首先我们先在一个干净的画布上生成九个格点:
clear
set obs 9
egen y = seq(), b(3)
egen x = seq(), t(3)
twoway (scatter y x)
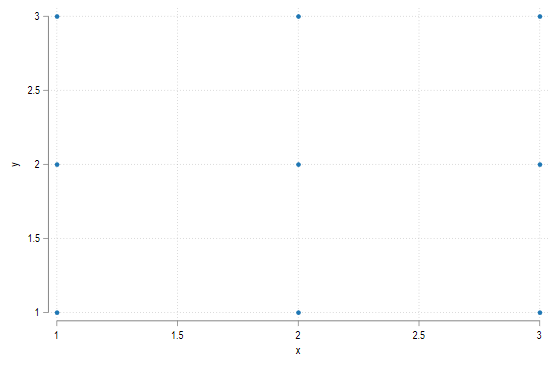
现在将这些点转化为方格,然后增加坐标轴的大小:
twoway (scatter y x, msymbol(square) msize(18)), xlabel(0 4) ylabel(0 4) aspect(1)
接下来把颜色放进去了,我们先看如何把对角的颜色填充进去:
colorpalette #e8e8e8 #dfb0d6 #be64ac #ace4e4 #a5add3 #8c62aa #5ac8c8 #5698b9 #3b4994, nograph
return list
local color11 `r(p1)'
local color12 `r(p2)'
local color13 `r(p3)'
local color21 `r(p4)'
local color22 `r(p5)'
local color23 `r(p6)'
local color31 `r(p7)'
local color32 `r(p8)'
local color33 `r(p9)'
twoway (scatter y x if x==1 & y==1, msymbol(square) msize(18) mc("`color11'")) ///
(scatter y x if x==2 & y==2, msymbol(square) msize(18) mc("`color22'")) ///
(scatter y x if x==3 & y==3, msymbol(square) msize(18) mc("`color33'")), ///
xlabel(0 4) ylabel(0 4) aspect(1) legend(off)
然后我们用循环的方法来快速填充其余的方格:
* 填充颜色
levelsof x, local(xlvl)
levelsof y, local(ylvl)
local boxes
foreach x of local xlvl {
foreach y of local ylvl {
local boxes `boxes' (scatter y x if x==`x' & y==`y', msymbol(square) ///
msize(19) mc("`color`x'`y''"))
}
}
cap drop spike*
gen spike1_x1 = 0.2 in 1
gen spike1_x2 = 3.6 in 1
gen spike1_y1 = 0.2 in 1
gen spike1_y2 = 0.2 in 1
gen spike1_m = "More African Americans"
gen spike2_y1 = 0.2 in 1
gen spike2_y2 = 3.2 in 1
gen spike2_x1 = 0.2 in 1
gen spike2_x2 = 0.2 in 1
gen spike2_m = "More Hispanics"
twoway `boxes' (pcarrow spike1_y1 spike1_x1 spike1_y2 spike1_x2, lcolor(gs12) lw(thin) /// mcolor(gs12) mlabel(spike1_m) mlabpos(7) headlabel) (pcarrow spike2_y1 spike2_x1 /// spike2_y2 spike2_x2, lcolor(gs12) lw(thin) mcolor(gs12) mlabel(spike2_m) mlabpos(10) /// headlabel mlabangle(90) mlabgap(1.8)), xlabel(0 4) ylabel(0 4) aspect(1) legend(off)
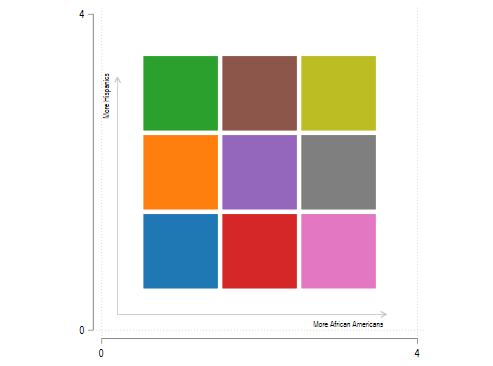
接下来将这张图的尺寸缩小以匹配我们之前绘制的地图,同时删掉原来的坐标轴和格点:
colorpalette #e8e8e8 #dfb0d6 #be64ac #ace4e4 #a5add3 #8c62aa #5ac8c8 #5698b9 #3b4994, nograph
return list
local color11 `r(p1)'
local color12 `r(p2)'
local color13 `r(p3)'
local color21 `r(p4)'
local color22 `r(p5)'
local color23 `r(p6)'
local color31 `r(p7)'
local color32 `r(p8)'
local color33 `r(p9)'
levelsof x, local(xlvl)
levelsof y, local(ylvl)
local boxes
foreach x of local xlvl {
foreach y of local ylvl {
local boxes `boxes' (scatter y x if x==`x' & y==`y', msymbol(square) msize(5) ///
mc("`color`x'`y''"))
}
}
twoway `boxes' (pcarrow spike1_y1 spike1_x1 spike1_y2 spike1_x2, lw(thin) /// lcolor(gs12) mcolor(gs12) mlabel(spike1_m) mlabpos(7 ) msize(0.8) headlabel /// mlabsize(2)) (pcarrow spike2_y1 spike2_x1 spike2_y2 spike2_x2, lw(thin) ///
lcolor(gs12) mcolor(gs12) mlabel(spike2_m) mlabpos(10) msize(0.8) headlabel /// mlabangle(90) mlabgap(1.8) mlabsize(2)), xlabel(0 4, nogrid) ylabel(0 4, nogrid) ///
aspectratio(1) xsize(1) ysize(1) fxsize(20) fysize(100) legend(off) ytitle("") ///
xtitle("") xscale(off) yscale(off) name(bivar_legend, replace)

最后我们将地图和这张小图例合在一起:
* 合并两张图
graph combine bivar_map bivar_legend, imargin(zero) ///
title("{fontface Arial Bold:Share of African Americans and Hispanics in the USA}", size(4.5)) ///
note("Source of data, and county and state layers: United States Census Bureau.", size(2))
6. 中国地图
set scheme white_tableau // 设置绘图模板
cap spshape2dta 省级数据
/*
这条命令可以将 dbf 和 shp 格式的地图文件转为两个 dta 格式的文件,分别以省级数据.dta
和省级数据_shp.dta命名,其中后者省级数据_shp.dta为坐标数据,前者省级数据.dta为标签数据,
在绘制地图时,我们主要是通过标签数据中的 ID 变量连接 (合并) 地图数据和作图数据
*/
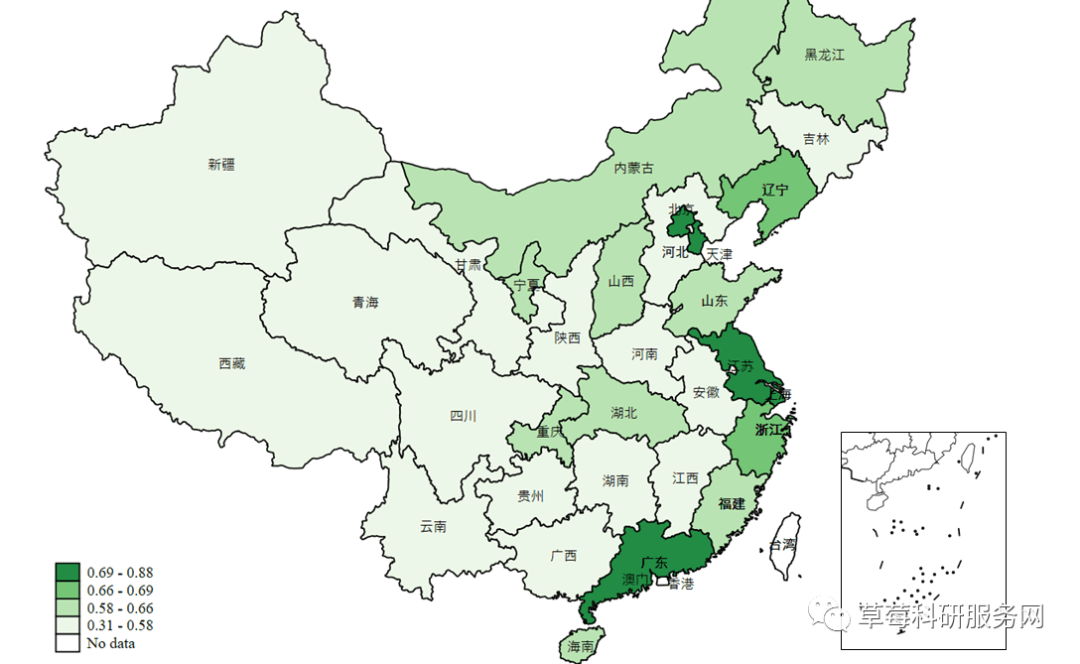
* 绘制一维地图
import excel 北京大学数字普惠金融指数.xlsx,firstrow sheet(Provinces) clear
// 使用总的数字金融普惠指数
collapse (mean) index_aggregate, by(prov_name)
drop in 1
save 普惠金融指数.dta,replace
ren prov_name name
merge 1:1 name using "省级数据.dta"
// drop in 32 // 由于北大普惠指数没有考虑香港、澳门、台湾,因此这些地区的数据缺失
drop _merge
spmap index_aggregate using 省级数据_shp, id(_ID) fcolor(Blues) mocolor(black) mosize(0.1)
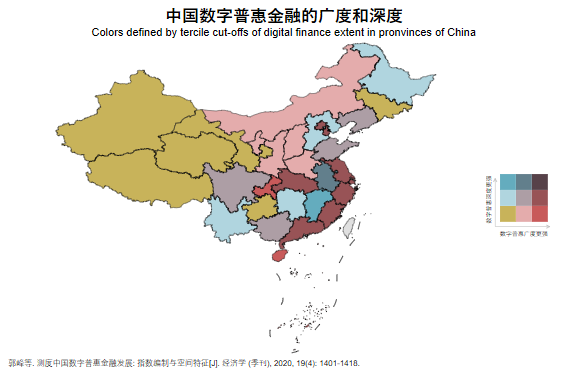
* 二维地图
import excel 北京大学数字普惠金融指数.xlsx, firstrow sheet(Provinces) clear
collapse (mean) coverage_breadth usage_depth, by(prov_name)
drop in 1
save 数字金融广度和深度.dta,replace
ren prov_name name
merge 1:1 name using "省级数据.dta"
// drop in 32
drop _merge
xtile xtile_coverage = coverage_breadth, n(3)
xtile xtile_usage = usage_depth, n(3)
sort xtile_coverage xtile_usage
cap drop xtile2
egen xtile2 = group(xtile_coverage xtile_usage)
// map with new color scheme
colorpalette #c8b35a #b0d5df #64acbe #e4acac #ad9ea5 #627f8c #c85a5a #985356 #574249, nograph
local colors `r(p)'
spmap xtile2 using 省级数据_shp, id(_ID) clm(unique) fcolor("`colors'") ///
ocolor(black ..) osize(0.02 ..) ///
ndfcolor(gs14) ndocolor(gs6 ..) ndsize(0.03 ..) ndlabel("No data") ///
polygon(data("省级数据_shp") ocolor(black) osize(0.12) ) ///
legend(off) name(bivar_map2, replace) mosize(vvvthick)
// legend with new color scheme
clear
set obs 9
egen y = seq(), b(3)
egen x = seq(), t(3)
cap drop spike*
gen spike1_x1 = 0.2 in 1
gen spike1_x2 = 3.6 in 1
gen spike1_y1 = 0.2 in 1
gen spike1_y2 = 0.2 in 1
gen spike1_m = "数字普惠广度更强"
gen spike2_y1 = 0.2 in 1
gen spike2_y2 = 3.2 in 1
gen spike2_x1 = 0.2 in 1
gen spike2_x2 = 0.2 in 1
gen spike2_m = "数字普惠深度更强"
colorpalette #c8b35a #b0d5df #64acbe #e4acac #ad9ea5 #627f8c #c85a5a #985356 #574249, nograph
local color11 `r(p1)'
local color12 `r(p2)'
local color13 `r(p3)'
local color21 `r(p4)'
local color22 `r(p5)'
local color23 `r(p6)'
local color31 `r(p7)'
local color32 `r(p8)'
local color33 `r(p9)'
levelsof x, local(xlvl)
levelsof y, local(ylvl)
local boxes
foreach x of local xlvl {
foreach y of local ylvl {
local boxes `boxes' (scatter y x if x==`x' & y==`y', msymbol(square) ///
msize(5) mc("`color`x'`y''"))
}
}
twoway`boxes' (pcarrow spike1_y1 spike1_x1 spike1_y2 spike1_x2, lw(thin) ///
lcolor(gs12) mcolor(gs12) mlabel(spike1_m) mlabpos(7) msize(0.8) ///
headlabel mlabsize(2)) (pcarrow spike2_y1 spike2_x1 spike2_y2 spike2_x2, ///
lw(thin) lcolor(gs12) mcolor(gs12) mlabel(spike2_m) mlabpos(10) msize(0.8) ///
headlabel mlabangle(90) mlabgap(1.8) mlabsize(2)), xlabel(0 4, nogrid) ///
ylabel(0 4, nogrid) aspectratio(1) xsize(1) ysize(1) fxsize(20) fysize(100) ///
legend(off) ytitle("") xtitle("") xscale(off) yscale(off) ///
name(bivar_legend2, replace)
// combine the two graphs
graph combine bivar_map2 bivar_legend2, imargin(zero) ///
title("{fontface Arial Bold:中国数字普惠金融的广度和深度}", size(4.5)) ///
subtitle("Colors defined by tercile cut-offs of digital finance extent in pronvinces of China", size(2.8)) ///
note("郭峰等. 测度中国数字普惠金融发展: 指数编制与空间特征[J]. 经济学 (季刊), 2020, 19(4): 1401-1418.", ///
size(2))
空间计量之用 spmap 绘制地图
在绘制地图时,大家可能会推荐 ArcGIS 等专业软件。然而,对于习惯使用 Stata 的用户而言,若数据管理、数据分析、绘图等各方面都能在 Stata 实现,那就太棒了!Stata 的绘图功能日益强大,能满足大多数可视化需求。现在,Stata 能通过外部命令 spmap 绘制出各式各样的地图,如下图所示:
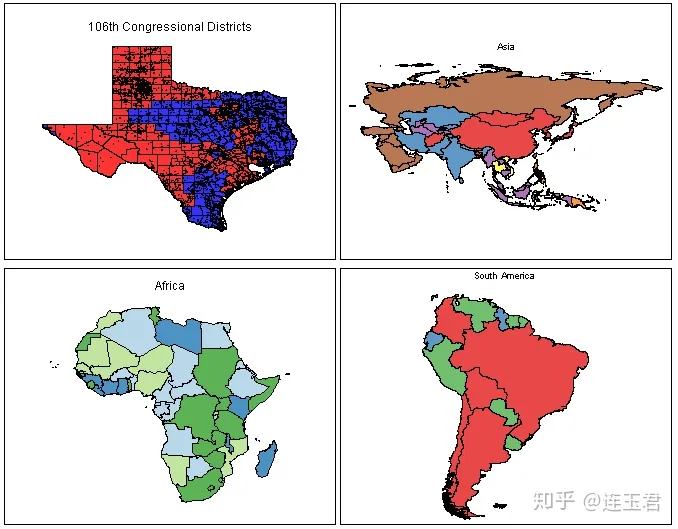
本文将详细介绍如何使用 spmap 命令绘制各种常用的地图。
1. 命令简介
外部命令 spmap (Pisati, 2007) 的前身为 tmap (Pisati, 2004)。Stata 15 版本的官方命令 grmap 改编自 spmap。相较 spmap, grmap 改动不大,但只用于空间数据 (spset data)。
由于篇幅有限,本推文只介绍 spmap。由于其命令的选项 (options) 较复杂,我们先熟悉绘制地图的一般步骤;再进一步了解其语法结构。
1.1 绘制步骤
参考 「Stata 官网提供的 FAQ」),绘制地图的一般步骤如下:
第一步:下载三个外部命令:spmap | shp2dta | mif2dta
*-Step 1: Obtain and install the spmap, shp2dta, and mif2dta commands
// 画地图的外部命令
ssc install spmap, replace
// 将外部的 dbf 文件和 shp 文件转化为 dta 文件
ssc install shp2dta, replace
// 将外部的 mif 文件和 mid 文件转化为 dta 文件
ssc install mif2dta, replace
* 获得帮助文件
help spmap
help shp2dta
help mif2dta
第二步:下载描绘地图的矢量数据文件
绘制地图时,一般需要两份数据:标签数据 (比如 ID 变量) 和地理坐标数据。对于后者,则有两种常用的矢量数据存储格式: ESRI shapefile (简称 shapefile)或 MapInfo Interchange Format。具体说明如下:
- ESRI shapefile 是美国环境系统研究所公司 (ESRI)) 开发的一种空间数据开放格式,用于存储地理要素的位置、形状和属性。Shapefile 通常有一个 .zip 压缩文件,包含多个文件,其中必须包括以下三个基本文件:
- 主文件 (*.shp): 存储几何要素的的空间信息,也就是 XY 坐标。
- 索引文件 (*.shx): 存储有关 .shp 存储的索引信息。它记录了在 .shp 中,空间数据是如何存储的,XY 坐标的输入点在哪里,有多少 XY 坐标对等信息。
- 表文件 (*.dbf): 存储地理数据的属性信息的 dBase 表。
用 Stata 绘制地图时,我们只需要 shape (*.shp) 和 dBase (*.dbf) 两个文件。 shp2dta 命令能帮助我们分别将这两个文件转成 Stata 专属的 .dta 格式的数据。
- MapInfo Interchange Format 是美国公司 MapInfo 开发的通用数据交换格式。这种格式是 ASCⅡ 码,可以编辑,易于生成,且可以工作在 MapInfo 支持的所有平台上。它将 MapInfo 数据保存于以下两个文件:
- *.mif 文件: 存储图形数据,可理解为 XY 坐标。
- *.mid 文件: 存储文本(属性)数据。
用 Stata 绘制地图时, mif2dta 命令能帮助我们分别将 *.mif 和 *.mid 文件转成 Stata 专属的 .dta 格式的数据。
Stata 范例:
Shapefiles 包含多种类型(比如,Polygon, Point, Polyine。)在绘制地图底图时,推荐使用 polygon shapefile。 一般地,ESRI shapefile 比 MapInfo Interchange Format 更易获得。我们可以在搜索引擎上获得 shapefiles。
本例子中,我们使用美国地图 shapefile 数据。获得 shapefile 文件步骤如下:
- 在 谷歌 或 雅虎 上搜 “United States shapefile”
- 在搜索结果中找到 https://www.weather.gov/gis/USStates
- 下载 s_11au16.zip (注:文件名会随数据的更新而改变。)
- 解压文件,我们只需两个文件:s_11au16.shp 和 s_11au16.dbf
更详细的操作介绍见下图:
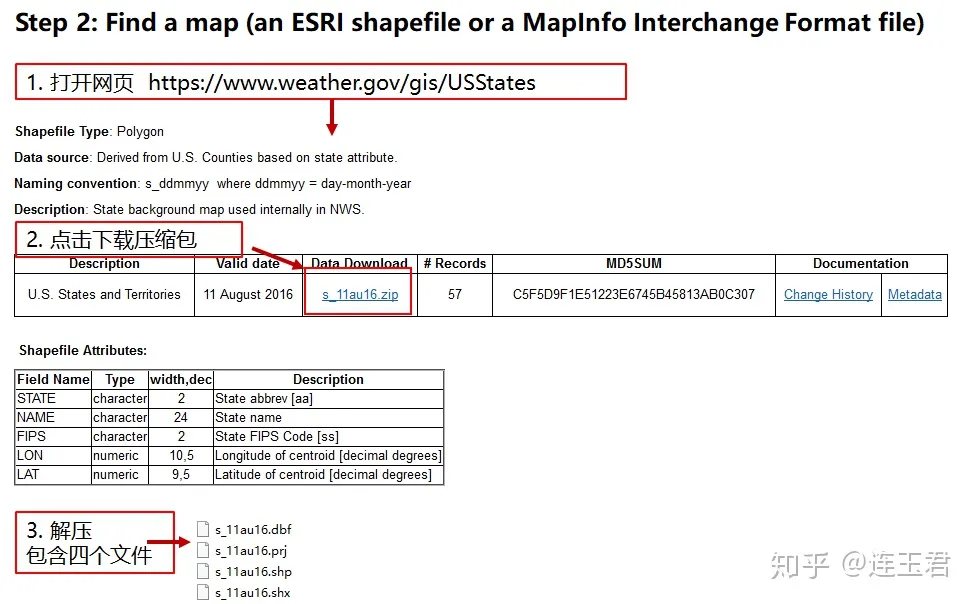
第三步:将地图的矢量数据文件转成 Stata 格式数据文件
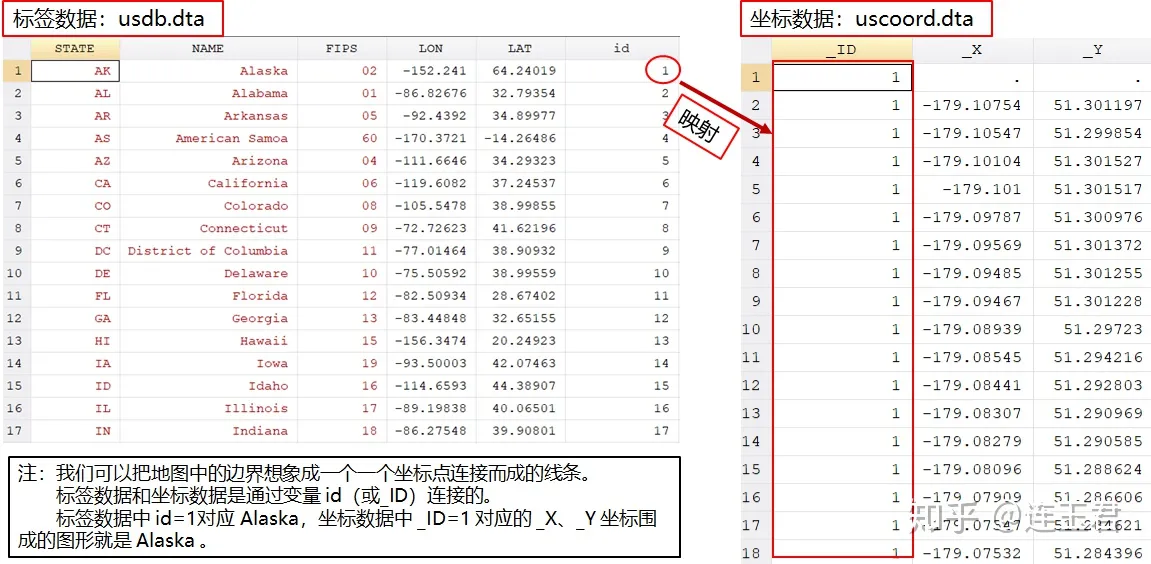
利用命令 shp2dta 或 mif2dta 将地图的矢量数据文件转成 Stata .dta 格式的数据。 检查 .dbf (.mid) 文件经转换后对应的 .dta 数据。该数据为标签数据,包含 ID 变量(命名为 id),不同 id 对应不同区域划分。我们应该了解地图矢量数据的提供者是如何划分区域的。比如,在一份数据中, id=1 对应 Alaska,id=2 对应 Alabama;而在另一份数据中,id=1 对应 Albania,id=2 对应 Argentina。
*-Step 3: Translate the files
* note:将数据放在当前工作路径
shp2dta using s_11au16, database(usdb) coordinates(uscoord) genid(id)
关于代码的一些说明:
database(usdb)将 database file 转换成 usdb.dta;coordinates(uscoord)将 coordinate file 转换成 uscoord.dta;genid(id)将 usdb.dta 中的 ID 变量命名为 id;- 转换 MapInfo files 时,语法一致,只需将 shp2dta 换成 mif2dta。
- 转换后的两个 .dta 文件如下:
第四步:将作图所需数据文件转换成 Stata 格式文件
具体而言,将我们需要作图的数据(attribute variable,比如,某年的人口数据)转换成 Stata 格式的 .dta 数据。
在绘制地图时,我们主要是通过标签数据中的 ID 变量连接(合并)地图数据和作图数据。我们需要保证不同数据中的 ID 变量对应的区域划分是一致的。
本例中,我们作图的数据为美国各州 1990 年的人口数据:stats.dta。 由于 stats.dta 中各州的 ID 变量为 scode ,与 usdb.dta 中的 ID 变量 id 编码不一致,我们生成一个中间文件 trans.dta,将 scode 与 id 对应起来。
*-Step 4: Determine the coding used by the map
* note:将数据放在当前工作路径
use stats, clear
merge 1:1 scode using trans
Result # of obs.
-----------------------------------------
not matched 0
matched 51 (_merge==3)
-----------------------------------------
drop _merge
*仔细检查合并的结果,确认无误后可删掉 _merge
*- _merge 变量的含义:
* _merge==1 obs. from master data
* _merge==2 obs. from only one using dataset
* _merge==3 obs. from at least two datasets, master or using
第五步:数据合并
将 .dbf (.mid) 文件经转换后对应的 .dta 数据与我们需要作图的 .dta 数据进行合并。
*-Step 5: Merge datasets
* note:将数据放在当前工作路径
merge 1:1 id using usdb
Result # of obs.
-----------------------------------------
not matched 6
from master 0 (_merge==1)
from using 6 (_merge==2)
matched 51 (_merge==3)
-----------------------------------------
drop if _merge!=3
(6 observations deleted)
drop _merge
*仔细检查合并的结果,确定无误后可删掉多余观测值
```
第六步:用 spmap 命令绘图
最后一步啦!可以用 spmap 命令进行画图!show your data!
*-Step 6: Draw the graph
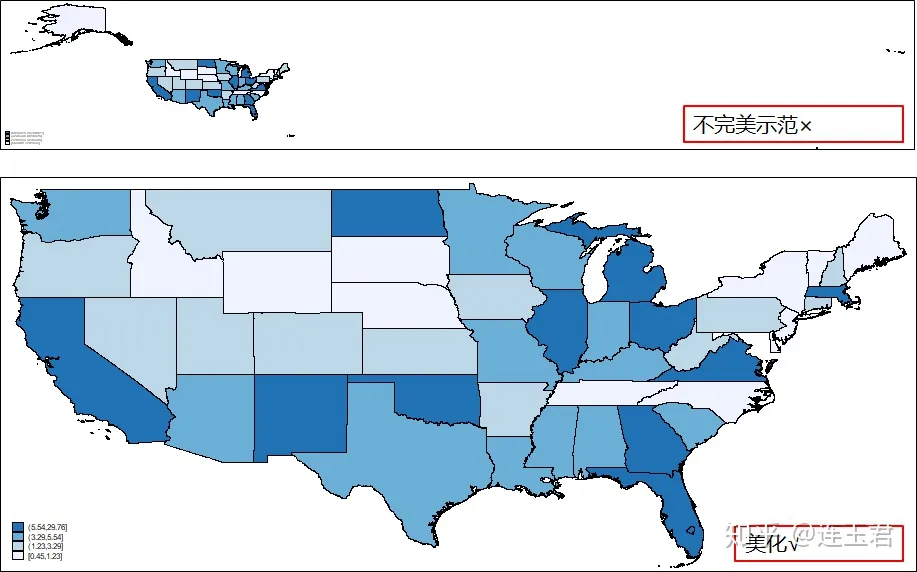
* 图1:不完美示范
spmap pop1990 using uscoord, id(id) fcolor(Blues)
* 图2:进一步美化
replace pop1990 = pop1990/1e+6
* 改变单位,避免图例里显示的数字过大
format pop1990 %4.2f
* 变量数据格式(整数与小数部分长度)
spmap pop1990 using uscoord ///
if id !=1 & id !=54 & ///
id !=39 & id !=56, ///
id(id) fcolor(Blues)
关于代码的一些说明:
- pop1990 是我们作图的数据(1990 年美国各州人口数据)。
- using uscoord 是必填项。绘制地图地图时,必需坐标数据(本例子中坐标数据为 uscoord.dta)。 - id(id) 是必填项。 绘制地图地图时,必需不同区域划分的 ID 变量(本例子中命名为 id)。
- fcolor(Blues) 是可选项,设置专题地图 (Choropleth map) 的填充颜色。本例中选用 Blues 主题,即以蓝色为主题色,不同区域会根据作图数据(本例中为人口数据)大小填充深浅不同的颜色。
- clnumber(#) 是可选项,设置分组数。
spmap默认基于分位数,将作图数据(本例中为人口数据)分为四组;若要自定义组数,则可加上该选项。- if 命令的使用:本例中使用
if去掉四个州,是因为这四个州分布过于分散,画出的图不美观。- 两幅图的对比如下:
1.2 命令的语法
该命令的基本语法如下:
spmap [attribute] [if] [in] using basemap [,
basemap_options
polygon(polygon_suboptions)
line(line_suboptions)
point(point_suboptions)
diagram(diagram_suboptions)
arrow(arrow_suboptions)
label(label_suboptions)
scalebar(scalebar_suboptions)
graph_options]
主要可选项说明如下:
basemap_options设置地图底图。- 其中最重要的选项为 id(idvar)。该选项必须加上,用来识别不同区域划分的 ID 变量 idvar。
- 其他选项用来控制底图的四个方面: Cartogram(比如背景色), Choropleth map(比如将作图数据分为几组), Format(比如填充颜色), Legend(比如是否显示图例)。
polygon(polygon_suboptions)在底图基础上添加其他多边形。line(line_suboptions)在底图基础上添加线条。point(point_suboptions)在底图基础上添加点。diagram(diagram_suboptions)在底图基础上添加条形/扇形统计图。arrow(arrow_suboptions)在底图基础上添加箭头。label(label_suboptions)在底图基础上添加文字标签。scalebar(scalebar_suboptions)设置比例尺。graph_options与我们常规画图的选项 (twoway_options) 基本一致。help spmap获得更多详细信息。
2. Stata 范例
目前,我们已经熟悉了绘制地图的一般步骤和语法结构。接下来我们将结合具体的例子进一步掌握 spmap 的使用方法。本节 2.2-2.4 的例子均来自 help spmap 帮助文件。官方提供的数据集可通过下述方式获得: net get spmap.pkg, from(http://fmwww.bc.edu/RePEc/bocode/s)
2.1 如何获得地图的矢量数据文件?
用 Stata 绘制地图至少需要两份数据:带有标签 (比如 ID 变量) 的数据和地理坐标数据。在 spmap 中,标签数据被称为 “master” dataset,地理坐标数据被称为 “basemap” dataset。
因此,我们绘图前必须先下载地图的矢量数据文件。若能直接下载 .dta 格式文件,则无需转换格式;若只能下载 shapefile (或 MapInfo Interchange Format) 格式的文件,则需用 shp2dta (或 mif2dta )将其转成 .dta 格式。
获得途径总结如下:
- 在搜索引擎上搜索关键词,比如 “中国地图 shapefile”。
- 在 GADM 网站上下载 shapefile 文件。该网站提供世界及世界各国的地图数据。
- 利用 Stata 命令,如下:
*-获得中国地图数据
copy "http://fmwww.bc.edu/repec/bocode/c/china_map.zip" china_map.zip, replace
unzipfile china_map, replace // 解压压缩文件
*-获得世界地图数据
use "http://fmwww.bc.edu/repec/bocode/w/world-c.dta",clear
save world-c.dta
use "http://fmwww.bc.edu/repec/bocode/w/world-d.dta",clear
save world-d.dta
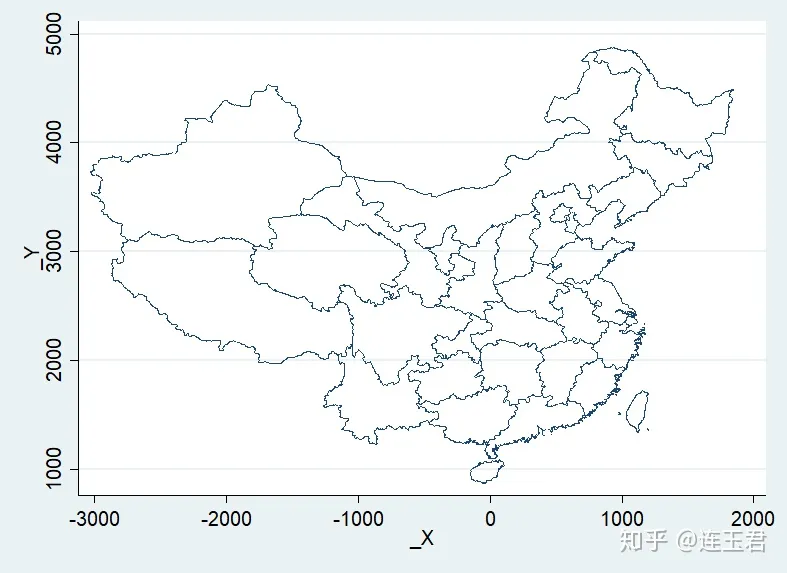
获得数据后,我们可利用 scatter 检查数据,看地图轮廓是否满足要求。
use "china_map.dta", clear
scatter _Y _X, msize(vtiny)
2.2 Stata 范例 1: Choropleth maps
Choropleth map 可翻译为 分级统计地图。在这种地图中,每个区域以不同深浅度的颜色表示数据变量。此法因常用色级表示,所以也叫色级统计图法。我们可简单理解为 “地图+热力:颜色渐变常见“。
use "Italy-RegionsData.dta", clear
#d ;
spmap relig1 using "Italy-RegionsCoordinates.dta", id(id)
title("Pct. Catholics without reservations", size(*0.8))
subtitle("Italy, 1994-98" " ", size(*0.8));
#d cr
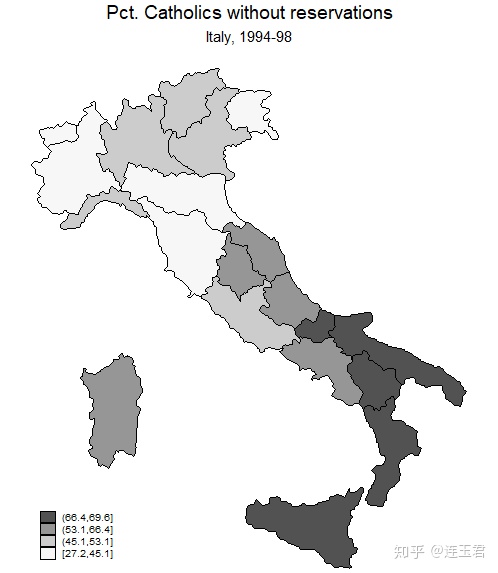
use "Italy-RegionsData.dta", clear
#d ;
spmap relig1m using "Italy-RegionsCoordinates.dta", id(id)
ndfcolor(red)
clmethod(eqint) clnumber(5) eirange(20 70)
title("Pct. Catholics without reservations", size(*0.8))
subtitle("Italy, 1994-98" " ", size(*0.8))
legstyle(2) legend(region(lcolor(black)));
#d cr
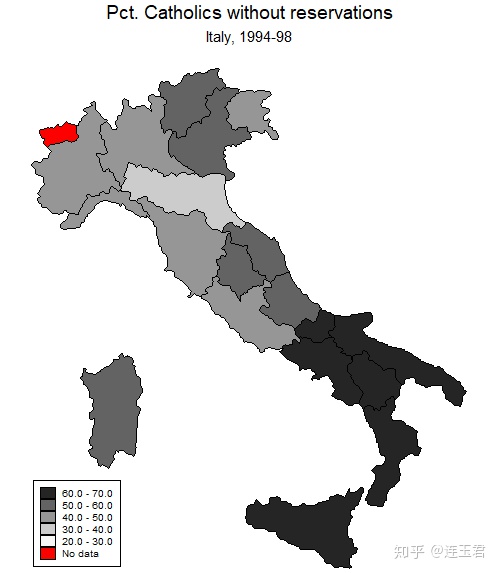
use "Italy-RegionsData.dta", clear
#d ;
spmap relig1 using "Italy-RegionsCoordinates.dta", id(id)
clnumber(20) fcolor(Reds2) ocolor(none ..)
title("Pct. Catholics without reservations", size(*0.8))
subtitle("Italy, 1994-98" " ", size(*0.8))
legstyle(3) legend(ring(1) position(3));
#d cr
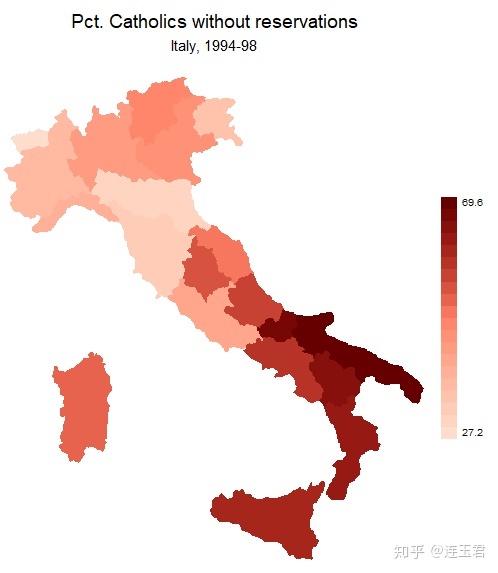
use "Italy-RegionsData.dta", clear
#d ;
spmap relig1 using "Italy-RegionsCoordinates.dta", id(id)
clnumber(20) fcolor(Greens2) ocolor(white ..) osize(thin ..)
title("Pct. Catholics without reservations", size(*0.8))
subtitle("Italy, 1994-98" " ", size(*0.8))
legstyle(3) legend(ring(1) position(3))
plotregion(icolor(stone)) graphregion(icolor(stone))
polygon(data("Italy-Highlights.dta") ocolor(white)
osize(medthick))
scalebar(units(500) scale(1/1000) xpos(-100) label(Kilometers));
#d cr
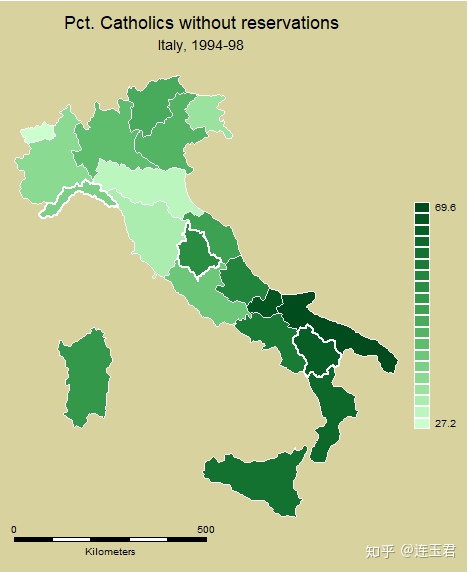
关于代码的一些说明:
- 官方直接提供了 dta 文件,所以我们在绘制地图时省略
shp2dta或mif2dta转换地图矢量数据文件的步骤。 ndfcolor(red)用红色表示缺失数据区域。clmethod(...)设置作图数据分组方式,默认是根据分位数分为 4 组。- 括号里可选填 quantile, boxplot, eqint, stdev, kmeans, custom, unique。
clmethod(eqint) clnumber(5) eirange(20 70):将作图数据按 20-70 范围等分为 5 组。clunmber(#)设置分组数。legstyle(#)设置图例显示模式,默认为 1,可选 2,3。- 1 显示为 (num,num];2 显示为 num-num;3 为色卡。
legend(...)设置图例是否带框线、摆放位置等。fcolor(...)设置填充颜色。icolor(...)设置背景色。ocolor(...)设置区域边界颜色。osize(...)设置区域边界线宽度。polygon(...)在底图 (basemap) 上添加其他多边形。scalebar(...)设置比例尺。
2.3 Stata 范例 2: Proportional symbol maps
Proportional symbol map 可理解为 带气泡的地图 (Bubble Map)。在这种地图中,气泡的面积代表了这个数据的大小。我们可简单理解为 “地图+气泡:圆越大数越大“。
我们可以通过添加选项 point(... proportional(propvar_pn) ...) 完成带气泡的地图。若我们想将气泡(圆)变成其他符号(比如为正方形),可在里面添加子选项 shape(s)。
若在该选项中去掉子选项 proportional(propvar_pn),则该图可退化为 点描法地图 (dot map),即气泡变为大小相等的点。我们可简单理解为 “地图+点:哪里有数点哪里“。
use "Italy-OutlineData.dta", clear
#d;
spmap using "Italy-OutlineCoordinates.dta", id(id)
title("Pct. Catholics without reservations", size(*0.8))
subtitle("Italy, 1994-98" " ", size(*0.8))
point(data("Italy-RegionsData.dta") xcoord(xcoord)
ycoord(ycoord) deviation(relig1) fcolor(red) dmax(30)
legenda(on) leglabel(Deviation from the mean));
#d cr
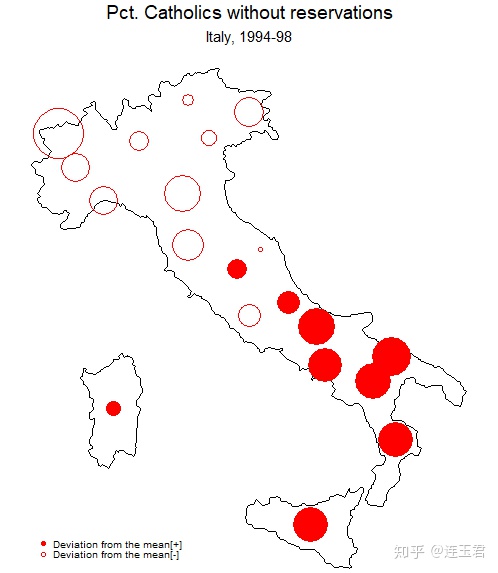
use "Italy-OutlineData.dta", clear
#d;
spmap using "Italy-OutlineCoordinates.dta", id(id)
title("Pct. Catholics without reservations", size(*0.8))
subtitle("Italy, 1994-98" " ", size(*0.8))
point(data("Italy-RegionsData.dta") xcoord(xcoord)
ycoord(ycoord) proportional(relig1) fcolor(green)
ocolor(white) size(*3))
label(data("Italy-RegionsData.dta") xcoord(xcoord)
ycoord(ycoord) label(relig1) color(white) size(*0.7));
#d cr
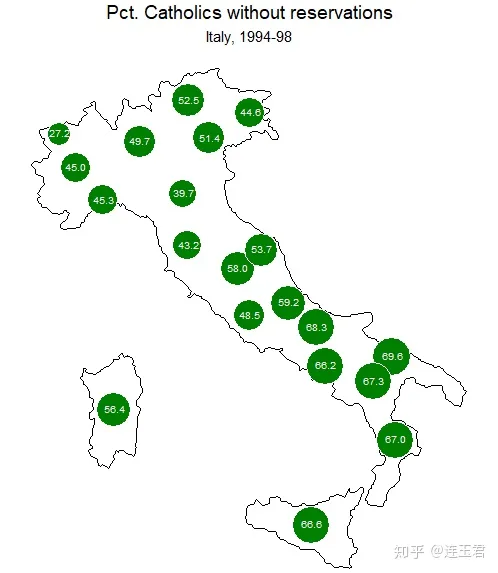
关于代码的一些说明:
- point(…)
在底图 (basemap) 上添加点。label(...)在底图 (basemap) 上添加标签(比如地名,数字等)。
2.4 Stata 范例 3: Other maps
我们还可以通过 spmap 画其他类型的图,比如在地图上添加条形图/扇形图。
use "Italy-RegionsData.dta", clear
#d ;
spmap using "Italy-RegionsCoordinates.dta", id(id) fcolor(stone)
title("Pct. Catholics without reservations", size(*0.8))
subtitle("Italy, 1994-98" " ", size(*0.8))
diagram(variable(relig1) range(0 100) refweight(pop98)
xcoord(xcoord) ycoord(ycoord) fcolor(red));
#d cr
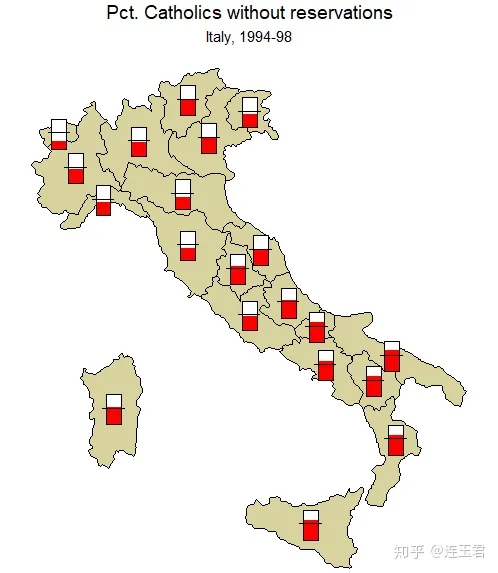
use "Italy-RegionsData.dta", clear
#d ;
spmap using "Italy-RegionsCoordinates.dta", id(id) fcolor(stone)
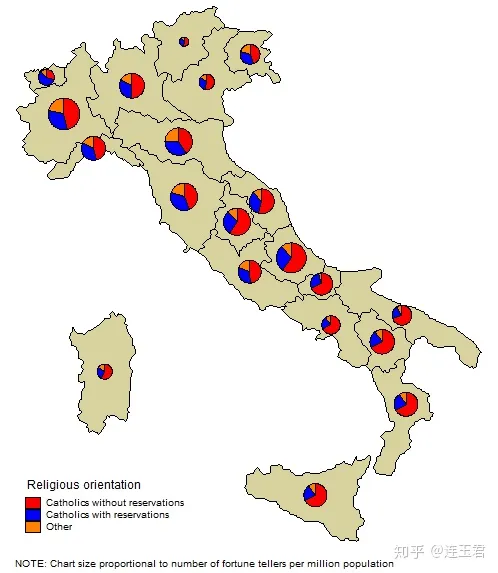
diagram(variable(relig1 relig2 relig3) proportional(fortell)
xcoord(xcoord) ycoord(ycoord) legenda(on))
legend(title("Religious orientation", size(*0.5) bexpand
justification(left)))
note(" "
"NOTE: Chart size proportional to number of fortune tellers per million population",
size(*0.75));
#d cr
use "Italy-OutlineData.dta", clear
#d ;
spmap using "Italy-OutlineCoordinates.dta", id(id) fc(bluishgray)
ocolor(none)
title("Provincial capitals" " ", size(*0.9) color(white))
point(data("Italy-Capitals.dta") xcoord(xcoord)
ycoord(ycoord) by(size) fcolor(orange red maroon) shape(s ..)
legenda(on))
legend(title("Population 1998", size(*0.5) bexpand
justification(left)) region(lcolor(black) fcolor(white))
position(2))
plotregion(margin(medium) icolor(dknavy) color(dknavy))
graphregion(icolor(dknavy) color(dknavy));
#d cr
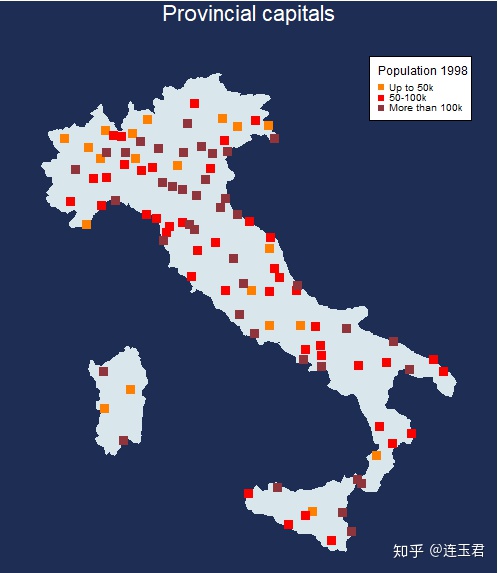
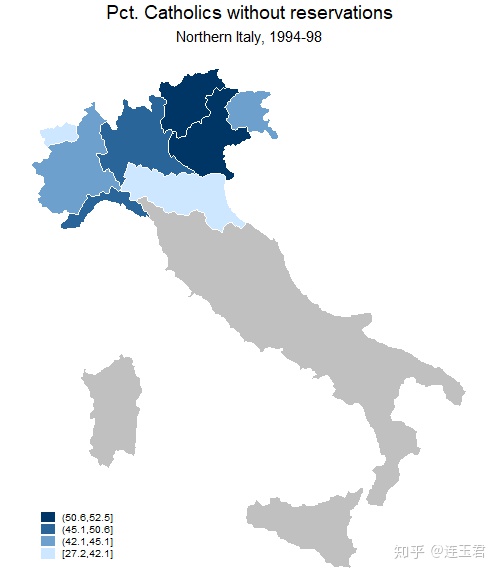
use "Italy-RegionsData.dta", clear
#d ;
spmap relig1 using "Italy-RegionsCoordinates.dta" if zone==1,
id(id) fcolor(Blues2) ocolor(white ..) osize(medthin ..)
title("Pct. Catholics without reservations", size(*0.8))
subtitle("Northern Italy, 1994-98" " ", size(*0.8))
polygon(data("Italy-OutlineCoordinates.dta") fcolor(gs12)
ocolor(white) osize(medthin)) polyfirst;
#d cr
use "Italy-OutlineData.dta", clear
#d ;
spmap using "Italy-OutlineCoordinates.dta", id(id) fc(sand)
title("Main lakes and rivers" " ", size(*0.9))
polygon(data("Italy-Lakes.dta") fcolor(blue) ocolor(blue))
line(data("Italy-Rivers.dta") color(blue) )
freestyle aspect(1.4) xlab(400000 900000 1400000, grid);
#d cr
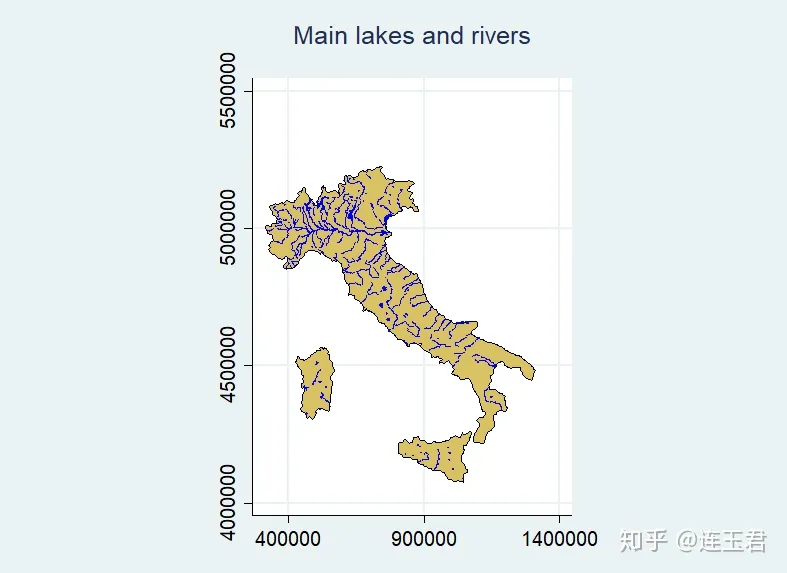
关于代码的一些说明:
polygon(...)在底图 (basemap) 上添加其他多边形。point(...)在底图 (basemap) 上添加点。line(...)在底图 (basemap) 上添加线条。- 绘制比较复杂的地图时,常用上述三个命令在底图 (basemap) 上叠加图层。
小结
用 Stata 绘制地图有两个关键点:一是获得地图的矢量数据文件,熟悉数据结构;二是熟悉命令 spmap 的语法结构。
基于Stata绘制2022年中国34个省域GDP空间分位图的演示
一、引言
可以绘制地图的软件除了ArcGIS以外,Stata、SAS等软件也可以。因为ASEF主要基于ArcGIS和Stata做相关研究,所以在特定环境下它更倾向于采用Stata绘制地图。Stata绘制地图的命令有官方命令grmap、非官方命令spmap等。关于spmap命令的演示,ASEF之前做过推文(基于Stata的ESDA(探索性空间数据分析)代码解析与实操验证),不再赘述。今天与大家一起学习,如何采用grmap命令绘制规范的中国标准地图。
二、演示
下面采用2022年中国34个省域的GDP数据进行空间分位图绘制演示。本演示共有四部分组成:(1)制作填色地图标签文件;(2)制作填色地图的值(本案例中为2022年中国34个省域的GDP)文件;(3)制作指北针文件;(4)绘制2022年中国34个省域GDP空间分位图。
第一部分为制作填色地图标签文件,程序如下:
clear
input Y X strL cname strL ename
2070000 155000 1000km 1000km
2200000 2480000 南海诸岛 "South China Sea"
2545645 577264 海南 HAINAN
2606862 -596605 N N
2793167 904743 澳门 MACAO SAR
2924472 1216567 香港 HONG KONG SAR
3033598 454021 广西 GUANGXI ZHUANGZU ZIZHIQU
3117659 901401 广东 GUANGDONG
3147149 -364398 云南 YUNAN
3171792 1723148 台湾 TAIWAN
3337393 223839 贵州 GUIZHOU
3359174 1310984 福建 FUJIAN
3448290 704352 湖南 HUNAN
3492625 1055225 江西 JIANGXI
3716572 273824 重庆 CHONGQING SHI
3753226 1458284 浙江 ZHEJIANG
3773471 -212006 四川 SICHUAN
3846593 688818 湖北 HUBEI
3994884 1142714 安徽 ANHUI
3997977 1543993 上海 SHANGHAI SHI
4038557 -1532343 西藏 XIZANG ZIZHIQU
4156136 1325927 江苏 JIANGSU
4174676 780159 河南 HENAN
4179103 341037 陕西 SHAANXI
4264787 -22066 甘肃 GANSU
4381696 -792836 青海 QINGHAI
4495014 1142137 山东 SHANDONG
4501152 99684 宁夏 NINGXIA HUIZU ZIZHIQU
4559114 621816 山西 SHANXI
4656767 917719 河北 HEBEI
4800073 1154470 天津 TIANJIN SHI
4936223 425619 内蒙古 "NEI MOGOL ZIZHIQU"
4981659 934732 北京 BEIJING SHI
5093605 1407783 辽宁 LIAONING
5113455 -1609429 新疆 XINJIANG ZIZHIQU
5409037 1625827 吉林 JILIN
5866667 1623938 黑龙江 HEILONGJIANG
end
compress
save 填色地图_标签, replace
第二部分为制作填色地图的值文件,程序如下:
clear
input 省代码 strL 省 ID GDP
110000 北京 1 4.16
120000 天津 2 1.63
130000 河北 3 4.24
140000 山西 4 2.56
150000 内蒙古 5 2.32
210000 辽宁 6 2.9
220000 吉林 8 1.31
230000 黑龙江 9 1.59
310000 上海 10 4.47
320000 江苏 11 12.29
330000 浙江 12 7.77
340000 安徽 13 4.5
350000 福建 14 5.31
360000 江西 15 3.21
370000 山东 16 8.74
410000 河南 17 6.13
420000 湖北 18 5.37
430000 湖南 19 4.87
440000 广东 20 12.91
450000 广西 21 2.63
460000 海南 22 0.68
500000 重庆市 23 2.91
510000 四川 24 5.67
520000 贵州 25 2.02
530000 云南 26 2.9
540000 西藏 27 0.21
610000 陕西 28 3.28
620000 甘肃 29 1.12
630000 青海 30 0.36
640000 宁夏 31 0.51
650000 新疆 32 1.77
710000 台湾 33 5.13
810000 香港 34 2.77
820000 澳门 35 0.22
end
compress
save 填色地图_值, replace
第三部分为制作指北针文件,程序如下:
clear
input _ID _X _Y value
38 . . 1
38 -600000 2200000 1
38 -600000 2500000 1
38 -500000 2160000 1
38 -600000 2200000 1
39 . . 1
39 -850000 2000000 1
39 -850000 2080000 1
39 -600000 2080000 1
39 -600000 2000000 1
39 -850000 2000000 1
39 . . 1
39 -350000 2000000 1
39 -350000 2080000 1
39 -100000 2080000 1
39 -100000 2000000 1
39 -350000 2000000 1
end
save 填色地图_指北针, replace
第四部分为绘制2022年中国34个省域GDP空间分位图,程序如下:
use 填色地图_值, clear
grmap GDP using chinaprov40_coord, id(ID) osize(vvthin ...) ocolor(white ...) clmethod(custom) clbreaks(-1 0 0.5 2 3 8 13) \\\
fcolor(gray "254 237 222" "253 190 133" "253 141 60" "230 85 13" "166 54 3") \\\
leg(order(2 "No Data" 3 "< 0.5" 4 "0.5~2" 5 "2~3" 6 "3~8" 7 "> 8")) \\\
graphr(margin(medium)) \\\
line(data(chinaprov40_line_coord.dta) select(keep if inlist(group, 1, 2, 3, 4, 5, 6)) by(group) size(vvthin *1 *0.5 *1.2 *0.5 *0.5) pattern(solid ...) color(white black "0 85 170" "24 188 156" black black)) \\\
polygon(data(填色地图_指北针) fcolor(black) osize(vvthin)) \\\
label(data(填色地图_标签) x(X) y(Y) label(cname) length(20) size(*0.6)) \\\
ti("2022年中国34个省域GDP空间分位图")
gr export 填色地图_输出.png, replace width(1200)
成图见图1。图1显示,2022年,广东、江苏、山东的GDP均居于全国前三名。
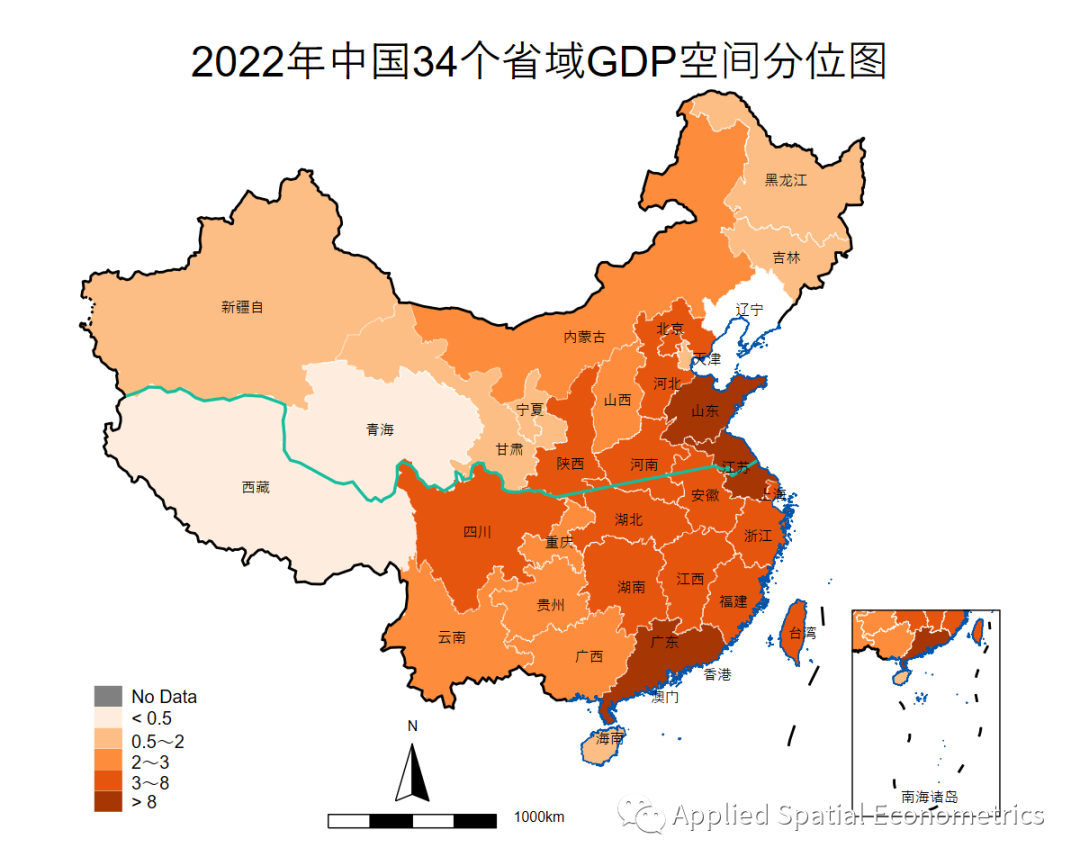
图1



